Configuring the Adapter for Apache Spark
|
Topics: |
|
How to: |
|
Reference: |
Configuring the adapter consists of specifying connection and authentication information for each of the connections you want to establish.
Procedure: How to Configure the Adapter for Apache Spark
You can configure the adapter from either the Web Console or the Data Management Console.
- From the
Web Console sidebar, click Connect to Data.
or
From the Data Management Console, expand the Adapters folder.
In the DMC, the Adapters folder opens. In the Web Console, the Adapters page opens showing your configured adapters.
- In the Web Console, click the New Datasource button on the menu bar and find the adapter on the page or, in the DMC, expand the Available folder if it is not already expanded.On the Web Console, you can select a category of adapter from the drop-down list or use the search option (magnifying glass) to search for specific characters.
- In the DMC, expand the appropriate group folder and the specific adapter folder. The group folder is described in the connection attributes reference.
- Right-click Apache Spark SQL and click Configure.
- In the URL box, type the URL used to connect to your Hive server. For more information, see Hive/Impala Adapter Configuration Settings.
- In the Driver Name box, type the driver name from the following table:
Driver JDBC Driver Name
Apache Spark
org.apache.hive.jdbc.HiveDriver
- Select the security type. If you are using Explicit,
type your user ID and password.
The following image shows an example of the configuration settings used:
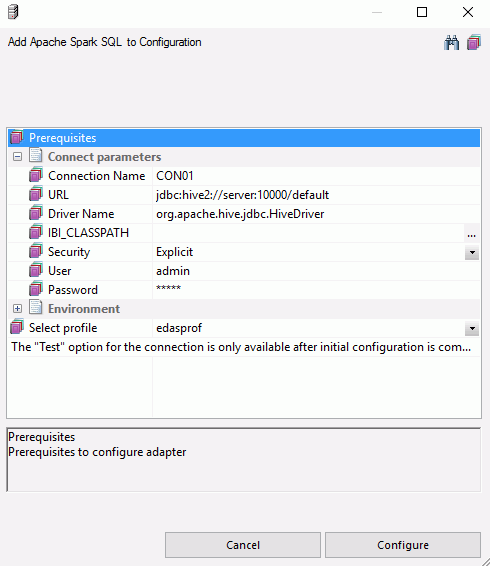
- Select edasprof from the Select profile drop-down menu to add this connection for all users, or select a user profile.
- Click Configure.
- Click Test. You should see a list of data sources on your server.
Reference: Adapter for Apache Spark Configuration Settings
The Adapter for Hadoop/Hive is under the SQL group folder.
- Connection name
-
Logical name used to identify this particular set of connection attributes. The default is CON01.
- URL
-
Is the URL to the location of the data source.
The URL used depends on what type of server you are connecting to. See the table below for examples.
Server
URL
Hiveserver2
jdbc:hive2://server:10000/default
Kerberos Hiveserver2 (static)
jdbc:hive2://server:10000/default; principal=hive/server@REALM.COM
Kerberos Hiveserver2 (user)
jdbc:hive2://server:10000/default;principal=hive/ server@REALM.COM; auth=kerberos;kerberosAuthType=fromSubject
where:
- server
-
Is the DNS name or IP address of the system where the Hive server is running. If it is on the same system, localhost can be used.
- default
-
Is the name of the default database to connect to.
- 10000
-
Is the default port number Spark Thrift Server is listening on if not specified when the Hive server is started.
- REALM.COM
-
For a Kerberos enabled Hive server, this Is the name of your realm.
- Driver Name
-
Is the name of the JDBC driver, org.apache.hive.jdbc.HiveDriver.
- IBI_CLASSPATH
-
Defines the additional Java Class directories or full-path jar names which will be available for Java Services. This value may be set by editing the communications file or in the Web Console. Using the Web Console, you can enter one reference per line in the input field. When the file is saved, the entries are converted to a single string using colon (:) delimiters for all platforms. OpenVMS platforms must use UNIX-style conventions when setting values (for example, /mydisk/myhome/myclasses.jar, rather than mydisk:[myhome]myclasses.jar). When editing the file manually, you must maintain the colon delimiter.
- Security
-
There are two methods by which a user can be authenticated when connecting to a database server:
- Explicit. The user ID and password are explicitly specified for each connection and passed to the database, at connection time, for authentication.
- Password Passthru. The user ID and password received from the client application are passed to the database, at connection time, for authentication.
- User
-
Primary authorization ID by which you are known to the data source.
- Password
-
Password associated with the primary authorization ID.
- Select profile
-
Select a profile from the drop-down menu to indicate the level of profile in which to store the CONNECTION_ATTRIBUTES command. The global profile, edasprof.prf, is the default.
If you wish to create a new profile, either a user profile (user.prf) or a group profile if available on your platform (using the appropriate naming convention), choose New Profile from the drop-down menu and enter a name in the Profile Name field (the extension is added automatically).
Store the connection attributes in the server profile (edasprof).
Kerberos
|
Topics: |
Connections to a Hive server with Kerberos enabled can be run in one of two ways:
- Static. The same Kerberos credential is used
for all connections. You must obtain a Kerberos ticket before starting
the server. On expiration of the Kerberos ticket, a new one must be obtained and the server must be restarted.
This mode is useful for testing, but is not recommended for production deployment.
- User. Each user connecting to the server connects to Hive using their own credentials from the Adapter for Apache Spark connection in the user profile. The server obtains a Kerberos ticket for the user.
To setup connections to a Kerberos enabled Spark Thrift Server instance if each user has their own connection, the Reporting Server has to be secured. The server can be configured with security providers PTH, LDAP, DBMS, OPSYS, or Custom, as well as multiple security provider environments.
Kerberos Static Ticket Requirements
In this configuration, all connections to the Spark Thrift Server instance will be done with the same Kerberos user ID derived from the Kerberos ticket that is created before the server starts.
- Create Kerberos ticket using:
kinit kerbid01
where:
- kerbid01
-
Is a Kerberos ID.
- Verify Kerberos ticket using klist. The following message
should be returned:

- Before configuring the Spark Thrift Server connection to a Kerberos-enabled instance, the connection should be tested. Use Beeline, the native tool, to test it.
- Start the server in the same Linux session where the Kerberos ticket was created. Log in to the Web Console and click the Adapters tab.
- Right-click Apache Spark SQL.
Use the following parameters to configure the adapter:
- URL
- Enter the same URL that you used to connect to the Hive Instance
using Beeline.
jdbc:hive2://server:10000/default;principal=hive/server@REALM.COM
- Security
-
Set to Trusted.
- In the Select profile drop-down menu, select the edasprof server profile.
- Click Configure.
- Next, configure Java services. Click the Workspace tab and expand the Java Services folder.
- Right-click DEFAULT and click Properties.
- Expand the JVM Settings section. In the
JVM options box, add the following:
-Djavax.security.auth.useSubjectCredsOnly=false
- Restart Java services.
Once these steps are completed, the adapter can be used to access a Kerberos-enabled Spark Thrift Server instance.
Kerberos User Ticket Requirements
In this configuration, each connected user has a Hive Adapter connection with Kerberos credentials in the user profile.
- Enable multi-user connection processing for Kerberos by
adding the following line to your profile (edasprof.prf):
ENGINE SQLSPK SET ENABLE_KERBEROS ON
- Configure the Hive Adapter Connection in the user profile using
the following values:
- URL
-
Is the URL to the location of the data source.
Server
URL
Kerberos Hiveserver2 (User)
jdbc:hive2://server:10000/default;principal=hive/server@REALM.COM; auth=kerberos;kerberosAuthType=fromSubject
- Security
-
Set to Explicit.
- User and Password
-
Enter your Kerberos user ID and password. The server will use those credentials to create a Kerberos ticket and connect to a Kerberos-enabled Spark Thrift Server instance.
Note: The user ID that you use to connect to the server does not have to be the same as the Kerberos ID you use to connect to a Kerberos-enabled Spark Thrift Server instance.
- Select Profile
-
Select your profile or enter a new profile name consisting of the security provider, an underscore and the user ID. For example, ldap01_pgmxxx.
- Click Configure.
Troubleshooting
If the server is unable to configure the connection, an error message is displayed. An example of the first line in the error message is shown below, where nnnn is the message number returned.
(FOC1400) SQLCODE IS -1 (HEX: FFFFFFFF) XOPEN: nnnn
Some common errors messages are:
[00000] JDBFOC>> connectx(): java.lang.UnsupportedClassVersionErr : or: org/apache/hive/jdbc/HiveDriver : Unsupported major.minor version 51.0
The adapter requires Java 1.7 or later and your JAVA_HOME points to Java 1.6.
(FOC1500) : ERROR: ncjInit failed. failed to connect to java server: JSS (FOC1500) : . JSCOM3 listener may be down - see edaprint.log for details
The server could not find Java. To see where it was looking, review the edaprint.log and set JAVA_HOME to the actual location. Finally, stop and restart your server.
(FOC1260) (-1) [00000] JDBFOC>> connectx(): java.lang.ClassNotFoundException: org.apache.hive.jdbc.HiveDriver (FOC1260) Check for correct JDBC driver name and environment variables. (FOC1260) JDBC driver name is org.apache.hive.jdbc.HiveDriver (FOC1263) THE CURRENT ENVIRONMENT VARIABLES FOR SUFFIX SQLHIV ARE : (FOC1260) IBI_CLASSPATH : ...
The JDBC driver name specified cannot be found in the jar files specified in IBI_CLASSPATH or CLASSPATH. The names of the jar files are either not specified, or if specified, do not exist in that location.
[08S0] Could not establish connection to jdbc:hive2://hostname:10000: java.net.UnknownHostException: hostname
The server hostname could not be reached on the network. Check that the name is spelled correctly and that the system is running. Check that you can ping the server.
[08S01] Could not establish connection to localhost:10000/default: : java.net.ConnectException: Connection refused
The Spark Thrift server is not listening on the specified port. Start the server if it is not running, and check that the port number is correct.
| WebFOCUS | |
|
Feedback |