Simplified Statistical Functions
The following simplified statistical functions have been added.
- CORRELATION, which returns the degree of correlation between two independent sets of data.
- KMEANS_CLUSTER, which partitions n observations into k clusters in which each observation belongs to the cluster with the nearest mean.
- STDDEV, which quantifies the amount of variation or dispersion of a set of data values.
- MULTIREGRESS, which derives a linear equation that best fits the data values of one or more numeric fields, and uses this equation to create a new column in the report output.
- RSERVE, which runs an R script that returns vector output.
These functions can be called in a COMPUTE command and operate on the internal matrix that is generated during TABLE request processing. The STDDEV and CORRELATION functions can also be called as a verb object in a display command.
Prior to calling a statistical function, you need to establish the size of the partition on which these functions will operate, if the request contains sort fields.
Note: It is recommended that all numbers and fields used as parameters to these functions be double-precision.
Syntax: How to Specify the Partition Size for Simplified Statistical Functions
SET PARTITION_ON = {FIRST|PENULTIMATE|TABLE} where:
- FIRST
-
Uses the first (also called the major) sort field in the request to partition the values.
- PENULTIMATE
-
Uses the next to last sort field where the COMPUTE is evaluated to partition the values. This is the default value.
- TABLE
-
Uses the entire internal matrix to calculate the statistical function.
CORRELATION: Calculating the Degree of Correlation Between Two Sets of Data
|
How to: |
The CORRELATION function calculates the correlation coefficient between two numeric fields. The function returns a numeric value between zero (0.0) and 1.0.
Syntax: How to Calculate the Correlation Coefficient Between Two Fields
CORRELATION(field1, field2)
where:
- field1
-
Numeric
Is the first set of data for the correlation.
- field2
-
Numeric
Is the second set of data for the correlation.
Example: Calculating a Correlation
CORRELATION calculates the correlation between DOLLARS and BUDDOLLARS.
CORRELATION(DOLLARS, BUDDOLLARS)
For DOLLARS=46,156,290.00 and BUDDOLLARS=46,220,778.00, the result is 0.895691073.
KMEANS_CLUSTER: Partitioning Observations Into Clusters Based on the Nearest Mean Value
|
How to: |
The KMEANS_CLUSTER function partitions observations into a specified number of clusters based on the nearest mean value. The function returns the cluster number assigned to the field value passed as a parameter.
Note: If there are not enough points to create the number of clusters requested, the value -10 is returned for any cluster that cannot be created.
Syntax: How to Partition Observations Into Clusters Based on the Nearest Mean Value
KMEANS_CLUSTER(number, percent, iterations, tolerance,
[prefix1.]field1[, [prefix1.]field2 ...])where:
- number
-
Integer
Is number of clusters to extract.
- percent
-
Numeric
Is the percent of training set size (the percent of the total data to use in the calculations). The default value is AUTO, which uses the internal default percent.
- iterations
-
Integer
Is the maximum number of times to recalculate using the means previously generated. The default value is AUTO, which uses the internal default number of iterations.
- tolerance
-
Numeric
Is a weight value between zero (0) and 1.0. The value AUTO uses the internal default tolerance.
- prefix1, prefix2
-
Defines an optional aggregation operator to apply to the field before using it in the calculation. Valid operators are:
- SUM. which calculates the sum of the field values. SUM is the default value.
- CNT. which calculates a count of the field values.
- AVE. which calculates the average of the field values.
- MIN. which calculates the minimum of the field values.
- MAX. which calculates the maximum of the field values.
- FST. which retrieves the first value of the field.
- LST. which retrieves the last value of the field.
Note: The operators PCT., RPCT., TOT., MDN., MDE., RNK., and DST. are not supported.
- field1
-
Numeric
Is the set of data to be analyzed.
- field2
-
Numeric
Is an optional set of data to be analyzed.
Example: Partitioning Data Values Into Clusters
The following request partitions the DOLLARS field values into four clusters and displays the result as a scatter chart in which the color represents the cluster. The request uses the default values for the percent, iterations, and tolerance parameters by passing them as the value 0 (zero).
SET PARTITION_ON = PENULTIMATE
GRAPH FILE GGSALES
PRINT UNITS DOLLARS
COMPUTE KMEAN1/D20.2 TITLE 'K-MEANS'= KMEANS_CLUSTER(4, AUTO, AUTO, AUTO, DOLLARS);
ON GRAPH SET LOOKGRAPH SCATTER
ON GRAPH PCHOLD FORMAT JSCHART
ON GRAPH SET STYLE *
INCLUDE=IBFS:/FILE/IBI_HTML_DIR/ibi_themes/Warm.sty,$
type = data, column = N2, bucket=y-axis,$
type=data, column= N1, bucket=x-axis,$
type=data, column=N3, bucket=color,$
GRID=OFF,$
*GRAPH_JS_FINAL
colorScale: {
colorMode: 'discrete',
colorBands: [{start: 1, stop: 1.99, color: 'red'}, {start: 2, stop: 2.99, color: 'green'},
{start: 3, stop: 3.99, color: 'yellow'}, {start: 3.99, stop: 4, color: 'blue'} ]
}
*END
ENDSTYLE
ENDThe output is shown in the following image.
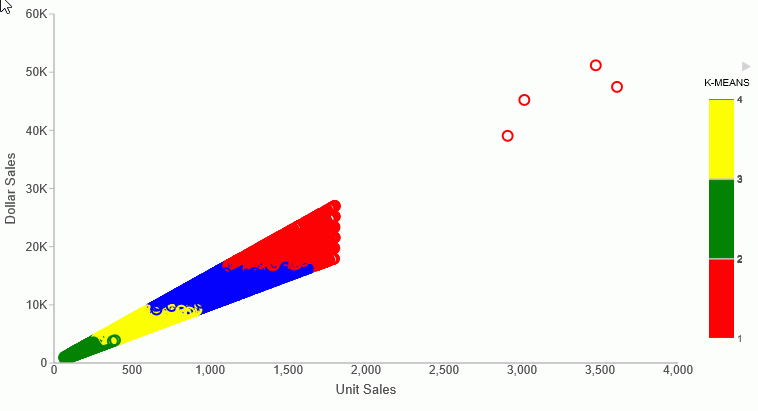
STDDEV: Calculating the Standard Deviation for a Set of Data Values
The STDDEV function returns a numeric value that represents the amount of dispersion in the data. The set of data can be specified as the entire population or a sample. The standard deviation is the square root of the variance, which is a measure of how observations deviate from their expected value (mean). If specified as a population, the divisor in the standard deviation calculation (also called degrees of freedom) will be the total number of data points, N. If specified as a sample, the divisor will be N-1.
If x¡ is an observation, N is the number of observations, and µ is the mean of all of the observations, the formula for calculating the standard deviation for a population is:
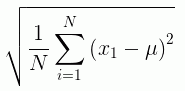
To calculate the standard deviation for a sample, the mean is calculated using the sample observations, and the divisor is N-1 instead of N.
Reference: Calculate the Standard Deviation in a Set of Data
STDDEV(field, sampling)
where:
- field
-
Numeric
Is the set of observations for the standard deviation calculation.
- sampling
-
Keyword
Indicates the origin of the data set. Can be one of the following values.
- P Entire population.
- S Sample of population.
Example: Calculating a Standard Deviation
STDDEV calculates the standard deviation of DOLLARS.
STDDEV(DOLLARS,S)
The result is 6,157.711080272.
MULTIREGRESS: Creating a Multivariate Linear Regression Column
|
How to: |
MULTIREGRESS derives a linear equation that best fits a set of numeric data points, and uses this equation to create a new column in the report output. The equation can be based on one or more independent variables.
The equation generated is of the following form, where y is the dependent variable and x1, x2, and x3 are the independent variables.
y = a1*x1 [+ a2*x2 [+ a3*x3] ...] + b
When there is one independent variable, the equation represents a straight line. When there are two independent variables, the equation represents a plane, and with three independent variables, it represents a hyperplane. You should use this technique when you have reason to believe that the dependent variable can be approximated by a linear combination of the independent variables.
Syntax: How to Create a Multivariate Linear Regression Column
MULTIREGRESS(input_field1, [input_field2, ...])
where:
- input_field1, input_field2 ...
-
Are any number of field names to be used as the independent variables. They should be independent of each other. If an input field is non-numeric, it will be categorized to transform it to numeric values that can be used in the linear regression calculation.
Example: Creating a Multivariate Linear Regression Column
The following request uses the DOLLARS and BUDDOLLARS fields to generate a regression column named Estimated_Dollars.
GRAPH FILE GGSALES
SUM BUDUNITS UNITS BUDDOLLARS DOLLARS
COMPUTE Estimated_Dollars/F8 = MULTIREGRESS(DOLLARS, BUDDOLLARS);
BY DATE
ON GRAPH SET LOOKGRAPH LINE
ON GRAPH PCHOLD FORMAT JSCHART
ON GRAPH SET STYLE *
INCLUDE=IBFS:/FILE/IBI_HTML_DIR/ibi_themes/Warm.sty,$
type=data, column = n1, bucket = x-axis,$
type=data, column= dollars, bucket=y-axis,$
type=data, column= buddollars, bucket=y-axis,$
type=data, column= Estimated_Dollars, bucket=y-axis,$
*GRAPH_JS
"series":[
{"series":2, "color":"orange"}]
*END
ENDSTYLE
ENDThe output is shown in the following image. The orange line represents the regression equation.
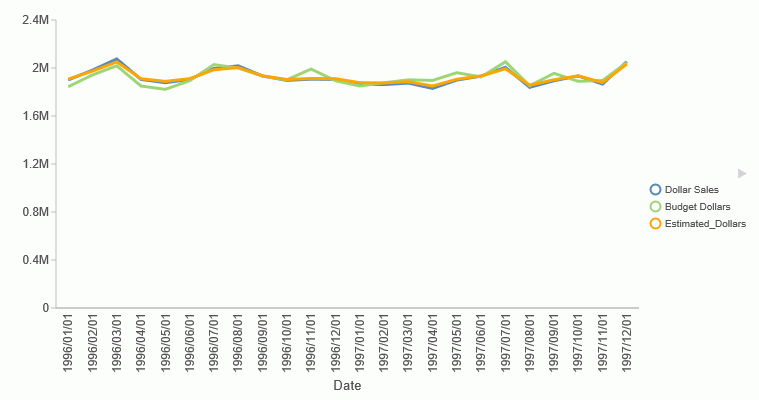
RSERVE: Running an R Script
|
How to: |
You can use the RSERVE function in a COMPUTE command to run an R script that returns vector output. This requires that you have a configured Adapter for Rserve.
Syntax: How to Run an R Script
RSERVE(rserve_mf, input_field1, ...input_fieldn, output)
where:
- rserve_mf
-
Is the synonym for the R script.
- input_field1, ...input_fieldn
-
Are the independent variables used by the R script.
- output
-
Is the dependent variable returned by the R script. It must be a single column (vector) of output.
Example: Using RESERVE to Run an R Script
The R script named wine_run_model.R predicts Bordeaux wine prices based on the average growing season temperature, the amount of rain during the harvest season, the amount of rain during the winter, and the age of the wine.
Using a configured connection (named MyRserve) for the Adapter for Rserve, and a sample data file named wine_input_sample.csv, you create the following synonym for the R script, as described in Statistics Adapters.
Master File
FILENAME=WINE_RUN_MODEL, SUFFIX=RSERVE , $
SEGMENT=INPUT_DATA, SEGTYPE=S0, $
FIELDNAME=AGST, ALIAS=AGST, USAGE=D9.4, ACTUAL=STRING,
MISSING=ON,
TITLE='AGST', $
FIELDNAME=HARVESTRAIN, ALIAS=HarvestRain, USAGE=I11, ACTUAL=STRING,
MISSING=ON,
TITLE='HarvestRain', $
FIELDNAME=WINTERRAIN, ALIAS=WinterRain, USAGE=I11, ACTUAL=STRING,
MISSING=ON,
TITLE='WinterRain', $
FIELDNAME=AGE, ALIAS=Age, USAGE=I11, ACTUAL=STRING,
MISSING=ON,
TITLE='Age', $
SEGMENT=OUTPUT_DATA, SEGTYPE=U, PARENT=INPUT_DATA, $
FIELDNAME=PRICE, ALIAS=Price, USAGE=D18.14, ACTUAL=STRING,
MISSING=ON,
TITLE='Price', $
Access File
SEGNAME=INPUT_DATA, CONNECTION=MyRserve, R_SCRIPT=/prediction/wine_run_model.r, R_SCRIPT_LOCATION=WFRS, R_INPUT_SAMPLE_DAT=prediction/wine_input_sample.csv, $
Now that the synonym has been created for the model, the model will be used to run against the following data file named wine_forecast.csv.
Year,Price,WinterRain,AGST,HarvestRain,Age,FrancePop 1952,7.495,600,17.1167,160,31,43183.569 1953,8.0393,690,16.7333,80,30,43495.03 1955,7.6858,502,17.15,130,28,44217.857 1957,6.9845,420,16.1333,110,26,45152.252 1958,6.7772,582,16.4167,187,25,45653.805 1959,8.0757,485,17.4833,187,24,46128.638 1960,6.5188,763,16.4167,290,23,46583.995 1961,8.4937,830,17.3333,38,22,47128.005 1962,7.388,697,16.3,52,21,48088.673 1963,6.7127,608,15.7167,155,20,48798.99 1964,7.3094,402,17.2667,96,19,49356.943 1965,6.2518,602,15.3667,267,18,49801.821 1966,7.7443,819,16.5333,86,17,50254.966 1967,6.8398,714,16.2333,118,16,50650.406 1968,6.2435,610,16.2,292,15,51034.413 1969,6.3459,575,16.55,244,14,51470.276 1970,7.5883,622,16.6667,89,13,51918.389 1971,7.1934,551,16.7667,112,12,52431.647 1972,6.2049,536,14.9833,158,11,52894.183 1973,6.6367,376,17.0667,123,10,53332.805 1974,6.2941,574,16.3,184,9,53689.61 1975,7.292,572,16.95,171,8,53955.042 1976,7.1211,418,17.65,247,7,54159.049 1977,6.2587,821,15.5833,87,6,54378.362 1978,7.186,763,15.8167,51,5,54602.193
The data file can be any type of file that R can read. In this case it is another .csv file. This file needs a synonym in order to be used in a report request. You create the synonym for this file using the Adapter for Delimited Files.
Following is the generated Master File, wine_forecast.mas.
FILENAME=WINE_FORECAST, SUFFIX=DFIX , CODEPAGE=1252,
DATASET=prediction/wine_forecast.csv, $
SEGMENT=WINE_FORECAST, SEGTYPE=S0, $
FIELDNAME=YEAR1, ALIAS=Year, USAGE=I6, ACTUAL=A5V,
MISSING=ON, TITLE='Year', $
FIELDNAME=PRICE, ALIAS=Price, USAGE=D8.4, ACTUAL=A7V,
MISSING=ON, TITLE='Price', $
FIELDNAME=WINTERRAIN, ALIAS=WinterRain, USAGE=I5, ACTUAL=A3V,
MISSING=ON, TITLE='WinterRain', $
FIELDNAME=AGST, ALIAS=AGST, USAGE=D9.4, ACTUAL=A8V,
MISSING=ON, TITLE='AGST', $
FIELDNAME=HARVESTRAIN, ALIAS=HarvestRain, USAGE=I5, ACTUAL=A3V,
MISSING=ON, TITLE='HarvestRain', $
FIELDNAME=AGE, ALIAS=Age, USAGE=I4, ACTUAL=A2V, MISSING=ON, TITLE='Age', $
FIELDNAME=FRANCEPOP, ALIAS=FrancePop, USAGE=D11.3, ACTUAL=A11V,
MISSING=ON, TITLE='FrancePop', $Following is the generated Access File, wine_forecast.acx.
SEGNAME=WINE_FORECAST, DELIMITER=',', ENCLOSURE=", HEADER=YES, CDN=COMMAS_DOT, CONNECTION=<local>, $
The following request, wine_forecast_price_report.fex, uses the RSERVE bulit-in function to run the script and return a report.
-*wine_forecast_price_report.fex
TABLE FILE PREDICTION/WINE_FORECAST
PRINT
YEAR
WINTERRAIN
AGST
HARVESTRAIN
AGE
COMPUTE PREDICTED_PRICE/D18.2 MISSING ON ALL=
RSERVE(prediction/wine_run_model, AGST, HARVESTRAIN, WINTERRAIN, AGE, Price); AS 'Predicted,Price'
ON TABLE SET PAGE NOLEAD
ON TABLE SET STYLE *
GRID=OFF,$
ENDSTYLE
END
The output is shown in the following image.
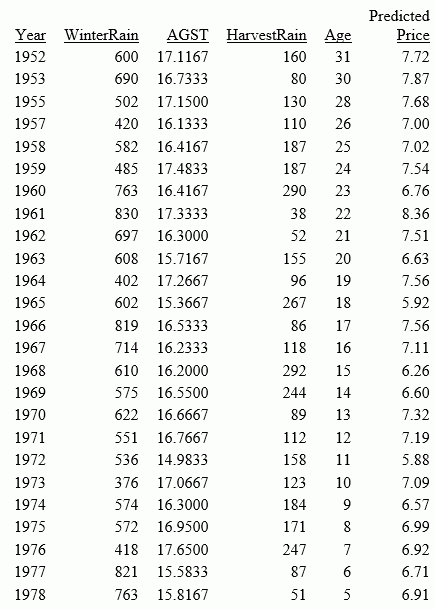
| WebFOCUS | |
|
Feedback |