Defining a Single Group of Fields
|
Topics: |
Certain fields in a data source may have a one-to-one correspondence. For each value of a field, the other fields may have exactly one corresponding value. For example, consider the EMPLOYEE data source:
- Each employee has one ID number which is unique to that employee.
- For each ID number there is one first and last name, one date hired, one department, and one current salary.
In the data source, one field represents each of these employee characteristics. The entire group of fields represents the employee. In Master File terms, this group is called a segment.
Understanding a Segment
A segment is a group of fields that have a one-to-one correspondence with each other and usually describe a group of related characteristics. In a relational data source, a segment is equivalent to a table. Segments are the building blocks of larger data structures. You can relate different segments to each other, and describe the new structures, as discussed in Relating Multiple Groups of Fields.
The following diagram illustrates the concept of a segment.
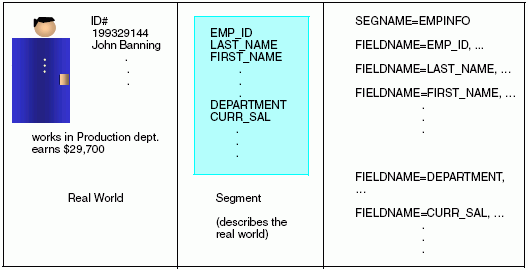
Understanding a Segment Instance
While a segment is an abstract description of data, the instances that correspond to it are the actual data. Each instance is an occurrence of segment values found in the data source. For a relational data source, an instance is equivalent to a row in a table. In a single segment data source, a segment instance is the same as a record.
The relationship of a segment to its instances is illustrated in the following diagram.
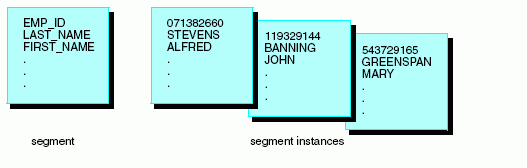
Understanding a Segment Chain
The instances of a segment that are descended from a single parent instance are collectively known as a segment chain. In the special case of a root segment, which has no parent, all of the root instances form a chain. The parent-child relationship is discussed in Logical Dependence: The Parent-Child Relationship.
The following diagram illustrates the concept of a segment chain.
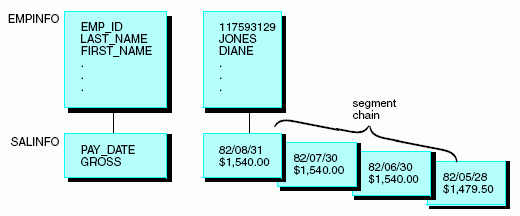
Describe a segment using the SEGNAME and SEGTYPE attributes in the Master File. The SEGNAME attribute is described in Identifying a Segment: SEGNAME.
Identifying a Key Field
Most segments also have key fields, which are one or more fields that uniquely identify each segment instance. In the EMPLOYEE data source, the ID number is the key because each employee has one ID number, and no other employee has the same number. The ID number is represented in the data source by the EMP_ID field.
If your data source uses an Access File, you may need to specify which fields serve as keys by identifying them in the Access File. If the data source also happens to be a relational data source, the fields constituting the primary key in the Master File should be the first fields described for that segment, meaning that the field declarations should come before any others in that segment.
For FOCUS data sources, identify key fields and their sorting order using the SEGTYPE attribute in the Master File, as shown in Describing a FOCUS Data Source. Position the key fields as the first fields in the segment.
Identifying a Segment: SEGNAME
|
How to: |
The SEGNAME attribute identifies the segment. It is the first attribute you specify in a segment declaration. Its alias is SEGMENT.
For a FOCUS data source, the segment name may consist of up to eight characters. Segment names for an XFOCUS data source may have up to 64 characters. You can use segment names of up to 64 characters for non-FOCUS data sources, if supported by the DBMS. To make the Master File self-documenting, set SEGNAME to something meaningful to the user or the native file manager. For example, if you are describing a DB2 table, assign the table name (or an abbreviation) to SEGNAME.
In a Master File, each segment name must be unique. The only exception to this rule is in a FOCUS or XFOCUS data source, where cross-referenced segments in Master File-defined joins can have the same name as other cross-referenced segments in Master File-defined joins. If their names are identical, you can still refer to them uniquely by using the CRSEGNAME attribute. See Defining a Join in a Master File.
In a FOCUS or XFOCUS data source, you cannot change the value of SEGNAME after data has been entered into the data source. For all other types of data sources, you can change SEGNAME as long as you also change all references to it. For example, any references in the Master and Access File.
If your data source uses an Access File as well as a Master File, you must specify the same segment name in both.
Syntax: How to Identify a Segment
{SEGNAME|SEGMENT} = segment_namewhere:
- segment_name
-
Is the name that identifies this segment. For a FOCUS data source, it can be a maximum of eight characters long. Segment names for an XFOCUS data source can consist of up to 64 characters. You can use segment names of up to 64 characters for non-FOCUS data sources, if supported by the DBMS.
The first character must be a letter, and the remaining characters can be any combination of letters, numbers, and underscores ( _ ). It is not recommended to use other characters, because they may cause problems in some operating environments or when resolving expressions.
Example: Identifying a Segment
If a segment corresponds to a relational table named TICKETS, and you want to give the segment the same name, use the SEGNAME attribute in the following way:
SEGNAME = TICKETS
| WebFOCUS | |
|
Feedback |