What is Unicode?
|
Topics: |
Unicode is a universal character encoding standard that assigns a code to every character and symbol in every language in the world. Since no other encoding standard supports all languages, Unicode is the only encoding standard that ensures that you can retrieve or combine data using any combination of languages. Unicode is required with XML, Java, JavaScript, LDAP, and other web-based technologies.
The two common Unicode implementations for computer systems are UTF-8, a variable length encoding scheme in which each written symbol is represented by a one- to four-byte code, and UTF-16, a fixed width encoding scheme in which each written symbol is represented by a two-byte code.
Information Builders supports UTF-8 Unicode on the WebFOCUS Reporting Server. The introduction of Unicode into Information Builders core text-handling facilities gives its products the flexibility to support true multilingual text. Using Unicode formatted data, WebFOCUS can produce a report containing data in any combination of languages (for example, Japanese and French). For details, see Unicode and the WebFOCUS Reporting Server.
UTF-8 Unicode is not a code page, but it is treated as such in Information Builders product architecture. Information Builders has created a code page of UTF-8 values for all supported scripts.
Why Use Unicode?
Unicode supports data with multiple scripts such as French, Japanese, and Hebrew. It enables you to combine records from different scripts on a single report. Before Unicode, a computer could only process and display the written symbols on its operating system code page, which was tied to a single script. For example, if a computer could process French, it could not process Japanese and Hebrew.
There is a growing trend for all new computer technologies to use Unicode for text data. In addition to Information Builders, Unicode has been adopted by industry leaders such as Microsoft, Apple®, HP®, IBM, Oracle®, SAP®, and many others. Many of the important data sources WebFOCUS accesses now support Unicode data types. The introduction of Unicode into WebFOCUS allows you to access and work directly with Unicode data and to create UTF-8 Unicode HOLD files.
Unicode is a preferred text encoding method in browsers such as Google Chrome and Firefox. Unicode is also used internally in Java technologies, HTML, XML, and Windows and Office. Unicode enables Information Builders products to seamlessly handle the interface with third-party facilities that use Unicode and are integrated into Information Builders product line.
Determining Whether Unicode Is Necessary
Configure your system for Unicode if you need to display text in unrelated scripts. There may be situations in which Unicode appears to be the only way to assimilate scripts, because you need to include third-party Unicode data. However, in many cases, Unicode is not the only solution.
For example, if you have Oracle data with a UTF-8 Unicode data type, but all the text is in Japanese and English, you do not need a full Unicode implementation. Japanese and English are not unrelated scripts. A Japanese code page is ASCII transparent. An ASCII-transparent code page contains the standard English language characters, as well as additional non-English characters.
Unicode is necessary only when combining text in unrelated scripts, such as Japanese, French, and Hebrew. For example, if your UTF-8 Unicode data contains Japanese text (unrelated scripts) displayed on a single report, UTF-8 Unicode is the only solution. In this situation, you would configure your entire system for UTF-8 Unicode.
Important: Full use of Unicode requires careful attention to browser, web server, and operating system characteristics. These characteristics include international language fonts, display and print features, and data input for unfamiliar scripts such as Chinese, and Japanese. Implement Unicode only if there is a real business need to combine unrelated scripts.
If you confirm that data in a data source (for example, Oracle) is coded in Unicode format, with text in different languages (for example, Japanese and English), you have two configuration options:
- Configure the WebFOCUS Reporting Server code page for
UTF-8 Unicode to access the Oracle data, but set the server client
code page for standard Japanese/English, such as Shift-JIS for Windows.
All the Japanese and English text appears correctly in a browser
set to the Shift-JIS encoding.
or
- Change the Oracle Relational Database Management System client code page to Shift-JIS, and configure the WebFOCUS Reporting Server for Shift-JIS on both the data source and client side.
In the second option, Oracle handles the transcoding from Unicode to Shift-JIS. Most of the relational and non-relational database management systems supported by Information Builders have the same code page architecture as WebFOCUS, which means they have an internal component, similar to Information Builders NLS API, that handles transcoding. Data source and client code page settings are typically set during installation or by editing settings in configuration files. For details, refer to the documentation of the specific vendor.
Defining the Alphanumeric Data Type
UTF-8 is a variable-length encoding scheme. In general, 7-bit ASCII characters (familiar English letters) are one byte, many European extended (national) characters are two bytes, and Double-Byte Character Set symbols (Japanese kanji) are three bytes.
Familiar alphanumeric data definitions such as SQL CHAR (n) or WebFOCUS An refer to bytes, not characters. However, more complex alphanumeric data types from Oracle and other vendors may refer to characters when their client side encoding is set to UTF-8.
In Unicode, one byte is not necessarily equal to one character, so be sure to allow enough space for alphanumerics.
Combining Data in Unrelated Scripts With Unicode
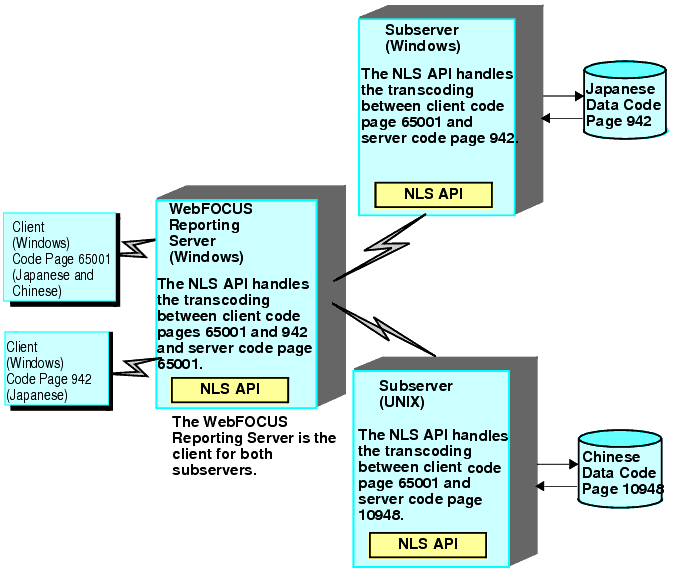
In the following scenario, Unicode is the only solution for combining data in two unrelated scripts, such as Japanese and Chinese. Without Unicode implementation, Japanese and Chinese, as unrelated scripts, are accessed using different code pages regardless of operating system. See the diagram in Combining Data in Unrelated Scripts With Unicode to see how unrelated scripts are combined.
In this scenario, the data sources may or may not be on two different operating systems.
Example: Combining Data in Unrelated Scripts With Unicode
This example shows how to combine data in unrelated scripts with Unicode.
- The two data sources have a common index key with a common range
of values to join them. One data source uses the Japanese Shift-JIS
code page 942, and the other data source uses the Traditional Chinese
code page 10948.
- Shift-JIS is Japanese PC data. It resides on a Windows subserver.
- Big-5 is Traditional Chinese UNIX or PC data. It can reside on either a UNIX platform or PC workstation. In this example, it resides on a UNIX subserver.
- While the two subservers have different server code page settings, both are configured to communicate with the same client code page (UTF-8 Unicode code page 65001). A UTF-8 Unicode configuration is the only solution for combining unrelated scripts.
- The WebFOCUS Reporting Server is the client for both subservers. Therefore, the subserver code page setting on the WebFOCUS Reporting Subserver (UTF-8 Unicode code page 65001) is the same as the client code page setting for the subservers (UTF-8 Unicode code page 65001).
- The WebFOCUS Reporting Server is configured to communicate with two client code pages (UTF-8 Unicode code page 65001 and Shift-JIS code page 942).
- One Windows client is a browser that is set to UTF-8 Unicode, so it can read both Japanese and Chinese data from code page 65001. The other Windows client is a browser that is set to Shift-JIS, so it can read Japanese data from code page 942. However, any Chinese data this second browser encounters will be displayed incorrectly.
- Multiple WebFOCUS Reporting Servers can usually run on the same computer as separate, intercommunicating processes. Therefore, all data sources, servers, subservers, and browsers could potentially run on a single machine. Shift-JIS (Japanese) and Traditional Chinese are unrelated scripts and cannot be combined without a Unicode solution. The processes may also run on separate computers, including a combination of UNIX and PC workstations as shown in the following image.
| WebFOCUS | |
|
Feedback |