Set-based Processing
Maintain Data provides the power of set-based processing, enabling you to read, manipulate, and write groups of records at a time. You manipulate these sets of data using a data structure called a data source stack.
A data source stack is a simple temporary table. Generally, columns in a data source stack correspond to data source fields, and rows correspond to records, or path instances, in that data source. You can also create your own user-defined columns.
The intersection of a row and a column is called a cell and corresponds to an individual field value. The data source stack itself represents a data source path.
For example, consider the following Maintain Data command:
FOR ALL NEXT Emp_ID Pay_Date Ded_Amt INTO PayStack
WHERE Employee.Emp_ID EQ SelectedEmpID;This command retrieves Emp_ID and the other root segment fields, as well as the Pay_Date, Gross, Ded_Code, and Ded_Amt fields from the Employee data source and holds them in a data source stack named PayStack. Because the command specifies FOR ALL, it retrieves all of the records at the same time. You do not need to repeat the command in a loop. Because it specifies WHERE, it retrieves only the records you need, in this case, the payment records for the currently-selected employee.
You could just as easily limit the retrieval to a sequence of data source records, such as the first six payment records that satisfy your selection condition
FOR 6 NEXT Emp_ID Pay_Date Ded_Amt INTO PayStack
WHERE Employee.Emp_ID EQ SelectedEmpID;or even restrict the retrieval to employees in the MIS department earning salaries above a certain amount:
FOR ALL NEXT Emp_ID Pay_Date Ded_Amt INTO PayStack
WHERE (Employee.Department EQ 'MIS') AND
(Employee.Curr_Sal GT 23000);Which Processes Are Set-based?
You can use set-based processing for the following types of operations:
- Selecting records. You can select a group of data source records at one time using the NEXT command with the FOR prefix. Maintain Data retrieves all of the data source records that satisfy the conditions you specified in the command and then automatically puts them into the data source stack that you specified.
- Collecting transaction values. You can use forms to display, edit, and enter values for groups of rows. The rows are retrieved from a data source stack, displayed in the form, and are placed back into a stack when the user is finished. You can also use the NEXT command to read values from a transaction file into a stack.
- Writing transactions to the data source. You can include, update, or delete a group of records at one time using the INCLUDE, UPDATE, REVISE, or DELETE commands with the FOR prefix. The records come from the data source stack that you specify in the command.
- Manipulating stacks. You can copy a set of records from one data source stack to another and sort the records within a stack.
The following diagram illustrates how these operations function together in a procedure:
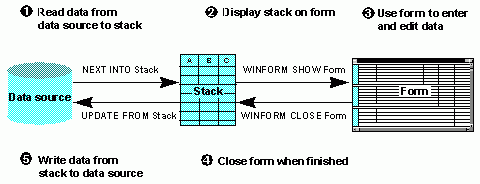
The diagram is explained in detail below:
- The procedure selects several records from the data source and, for each record, copies the values for fields A, B, and C into the data source stack. It accomplishes this using the NEXT command.
- The procedure displays a form on the screen. The form shows multiple instances of fields A, B, and C. The field values shown on the screen are taken from the stack. This is accomplished using a form and the Winform Show command.
- The procedure user views the form and enters and edits data. As the form responds to the activity of the user, it automatically communicates with the procedure and updates the stack with the new data.
- The procedure user clicks a button to exit the form. The button accomplishes this by triggering the Winform Close command.
- The procedure writes the values for fields A, B, and C from the stack to the selected records in the data source. The procedure accomplishes this using the UPDATE command.
How Does Maintain Data Process Data in Sets?
Maintain Data processes data in sets using two features:
- The command prefix FOR. When you specify FOR at the beginning of the NEXT, INCLUDE, UPDATE, REVISE, and DELETE commands, the command works on a group of records, instead of on just one record.
- Stacks. You use a data source stack to hold the data from a group of data source or transaction records. For example, a stack can hold the set of records that are output from one command (such as NEXT or Winform) and provide them as input to another command (such as UPDATE). This enables you to manipulate the data as a group.
Creating and Defining Data Source Stacks: An Overview
Maintain Data makes working with stacks easy by enabling you to create and define a data source stack dynamically, simply by using it. For example, when you specify a particular stack as the destination stack for a data source retrieval operation, that stack is defined as including all of the fields in all of the segments referred to by the command. Consider the following NEXT command, which retrieves data from the VideoTrk data source into the stack named VideoTapeStack:
FOR ALL NEXT CustID INTO VideoTapeStack;
Because the command refers to the CustID field in the Cust segment, all of the fields in the Cust segment (from CustID through Zip) are included as columns in the stack. Every record retrieved from the data source is written as a row in the stack.
Example: Creating and Populating a Simple Data Source Stack
If you are working with the VideoTrk data source, and you want to create a data source stack containing the ID and name of all customers whose membership expired after June 24, 1992, you could issue the following NEXT command:
FOR ALL NEXT CustID INTO CustNames WHERE ExpDate GT 920624;
The command does the following:
- Selects (NEXT) all VideoTrk records (FOR ALL) that satisfy the membership condition (WHERE).
- Copies all of the fields from the Cust segment (referenced by the CustID field) from the selected data source records into the CustNames stack (INTO).
The resulting CustNames stack looks like this (some intervening columns have been omitted to save space):
|
CustID |
LastName |
... |
Zip |
|---|---|---|---|
|
0925 |
CRUZ |
... |
61601 |
|
1118 |
WILSON |
... |
61601 |
|
1423 |
MONROE |
... |
61601 |
|
2282 |
MONROE |
... |
61601 |
|
4862 |
SPIVEY |
... |
61601 |
|
8771 |
GARCIA |
... |
61601 |
|
8783 |
GREEN |
... |
61601 |
|
9022 |
CHANG |
... |
61601 |
Creating a Data Source Stack
You create a data source stack:
- Implicitly,
by specifying it in a NEXT or MATCH command as the destination (INTO)
stack, or by associating it in the HTML canvas.
Forms are introduced in Forms and Event-driven Processing. The HTML canvas is used to design and create forms.
- Explicitly, by declaring it in an INFER command.
For example, this NEXT command creates the EmpAddress stack:
FOR ALL NEXT StreetNo INTO EmpAddress;
Defining Data Source Columns in a Data Source Stack
When you define a data source stack, you can include any field along a data source path. Maintain Data defines the data source columns of a stack by performing the following steps:
- Scanning the procedure to identify all the NEXT, MATCH, and INFER commands that use the stack as a destination and all the controls that use the stack as a source or destination.
- Identifying the data source fields that
these commands move in or out of the stack:
- NEXT commands. Moves the fields in the data source field list and WHERE phrase.
- MATCH commands. Moves the fields in the data source field list.
- INFER commands. Moves all the fields specified by the command.
- Identifying the data source path that contains these fields.
- Defining the
stack to include columns corresponding to all the fields in this
path.
- NEXT commands. Moves the fields in the data source field list and WHERE phrase.
- MATCH commands. Moves the fields in the data source field list.
- INFER commands. Moves all the fields specified by the command.
You can include any number of segments in a stack, as long as they all come from the same path. When determining a path, unique segments are interpreted as part of the parent segment. The path can extend through several data sources that have been joined together. Maintain Data supports joins that are defined in a Master File. For information about defining joins in a Master File, see the Describing Data With WebFOCUS Language manual. (Maintain Data can read from joined data sources, but cannot write to them.)
The highest specified segment is known as the anchor and the lowest specified segment is known as the target. Maintain Data creates the stack with all of the segments needed to trace the path from the root segment to the target segment:
- It automatically includes all fields from all of the segments in the path that begins with the anchor and continues to the target.
- If the anchor is not the root segment, it automatically includes the key fields from the anchor's ancestor segments.
Example: Defining Data Source Columns in a Data Source Stack
In the following source code, a NEXT command refers to a field (Last_Name) in the EmpInfo segment of the Employee data source, and reads that data into EmpStack. Another NEXT command refers to a field (Salary) in the PayInfo segment of Employee and also reads that data into EmpStack.
NEXT Last_Name INTO EmpStack; . . . FOR ALL NEXT Salary INTO EmpStack;
Based on these two NEXT commands, Maintain Data defines a stack named EmpStack, and defines it as having columns corresponding to all of the fields in the EmpInfo and PayInfo segments:
|
Emp_ID |
Last_Name |
... |
Ed_Hrs |
Dat_Inc |
... |
Salary |
JobCode |
|---|---|---|---|---|---|---|---|
|
071382660 |
STEVENS |
... |
25.00 |
82/01/01 |
... |
$11,000.00 |
A07 |
|
071382660 |
STEVENS |
... |
25.00 |
81/01/01 |
... |
$10,000.00 |
A07 |
Example: Establishing a Path Using Keys and Anchor and Target Segments
The following code populates CustMovies, a data source stack that contains video rental information for a given customer. The first NEXT command identifies the customer. The second NEXT command selects a field (TransDate) from the second segment and a field (Title) from the bottom segment of a path that runs through the joined VideoTrk and Movies data sources:
NEXT CustID WHERE CustID IS '7173'; FOR ALL NEXT TransDate Title INTO CustMovies WHERE Category IS 'COMEDY';
The structure of the joined VideoTrk and Movies data sources looks like this:
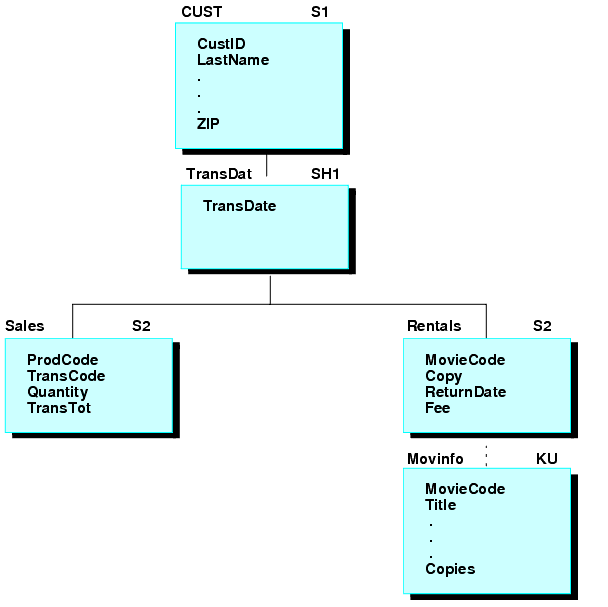
In this NEXT command, the TransDat segment is the anchor and the MovInfo segment is the target. The resulting CustMovies stack contains all the fields needed to define the data source path from the root segment to the target segment:
- The ancestor segment of the anchor, Cust (key field only).
- All segments from the anchor through the root: TransDat, Rentals, MovInfo (all fields).
The stack looks like this:
|
CustID |
TransDate |
MovieCode |
... |
Title |
... |
Copies |
|---|---|---|---|---|---|---|
|
7173 |
91/06/18 |
305PAR |
... |
AIRPLANE |
... |
2 |
|
7173 |
91/06/30 |
651PAR |
... |
MY LIFE AS A DOG |
... |
3 |
Creating Data Source Stack User-Defined Columns
In addition to creating data source stack columns that correspond to data source fields, you can also create data source stack columns that you define yourself. You can define these columns in two ways:
- Within a procedure. You
can create a stack column, as well as user-defined variables, by
issuing a COMPUTE command. You can also use the COMPUTE command
to assign values to stack cells.
Because all Maintain Data variables are local to a procedure, you must redefine variables in each procedure in which you use them. For user-defined stack columns, you accomplish this by simply reissuing the original COMPUTE command in each procedure to which you are passing the stack. You only need to specify the format of the variable. You do not need to specify its value, which is passed with the stack.
- Within the Master File. You
can define a virtual field in a Master File by using the DEFINE
attribute. The field is then available in every procedure that accesses the
data source. The virtual field is treated as part of the data source
segment in which it is defined, and Maintain Data automatically
creates a corresponding column for it, a virtual column, in every
stack that references that segment.
Virtual fields must be derived, directly or indirectly, from data source values. They cannot be defined as a constant. The expression assigned to a virtual field in the Master File can reference fields from other segments in the same data source path as the virtual field.
Unlike other kinds of stack columns, you cannot update a virtual column or field, and you cannot test it in a WHERE phrase.
Example: Creating a User-Defined Column
Consider a data source stack named Pay that contains information from the Employee data source. If you want to create a user-defined column named Bonus and set its value to 10% of the current salary of each employee, you could issue the COMPUTE command to create the new column, and then issue another COMPUTE to derive the value. You place the second COMPUTE within a REPEAT loop to run it once for each row in the stack:
COMPUTE Pay.Bonus/D10.2;
REPEAT Pay.FocCount Row/I4=1;
COMPUTE Pay(Row).Bonus = Pay(Row).Curr_Sal * .10;
ENDREPEAT Row=Row+1;Copying Data Into and Out of a Data Source Stack
You can copy data into and out of a data source stack in the following ways:
- Between a stack and a data source. You can copy data from a data source into a stack using the NEXT and MATCH commands. You can copy data in the opposite direction, from a stack into a data source, using the INCLUDE, UPDATE, and REVISE commands. In addition, the DELETE command, while not actually copying a stack data, reads a stack to determine which records to remove from a data source. For more information about these commands, see Command Reference in the Maintain Data Language Reference manual.
- Between a stack and a form. You can copy data from a stack into a form, and from a form into a stack, by specifying the stack as the source or destination of the data displayed by the form. This technique makes it easy for an application user to enter and edit stack data at a personal computer.
- From a transaction file to a stack. You can copy data from a transaction file to a stack using the NEXT command. For more information about this command, see the Maintain Data Language Reference manual.
- Between two stacks. You can copy data from one stack to another using the COPY and COMPUTE commands. For more information about these commands, see Command Reference in the Maintain Data Language Reference manual.
You can use any of these commands to copy data by employing the command INTO and FROM phrases. FROM specifies the command data source (the source stack), and INTO specifies the command data destination (the destination stack).
Example: Copying Data Between a Data Source Stack and a Data Source
In this NEXT command
FOR ALL NEXT CustID INTO CustStack;
the INTO phrase copies the data (the CustID field and all of the other fields in that segment) into CustStack. The following UPDATE command
FOR ALL UPDATE ExpDate FROM CustStack;
uses the data from CustStack to update records in the data source.
Referring to Specific Stack Rows Using an Index
Each stack has an index that enables you to refer to specific rows. For example, by issuing a NEXT command, you create the CustNames stack to retrieve records from the VideoTrk data source:
FOR ALL NEXT CustID LastName INTO CustNames
WHERE ExpDate GT 920624;The first record retrieved from VideoTrk becomes the first row in the data source stack, the second record becomes the second row, and so on.
|
|
CustID |
LastName |
... |
Zip |
|---|---|---|---|---|
|
1 |
0925 |
CRUZ |
... |
61601 |
|
2 |
1118 |
WILSON |
... |
61601 |
|
3 |
1423 |
MONROE |
... |
61601 |
|
4 |
2282 |
MONROE |
... |
61601 |
|
5 |
4862 |
SPIVEY |
... |
61601 |
|
6 |
8771 |
GARCIA |
... |
61601 |
|
7 |
8783 |
GREEN |
... |
61601 |
|
8 |
9022 |
CHANG |
... |
61601 |
You can refer to a row in the stack by using a subscript. The following example refers to the third row, in which CustID is 1423:
CustNames(3)
You can use any integer value as a subscript: an integer literal (such as 3), an integer field (such as TransCode), or an expression that resolves to an integer (such as TransCode + 2).
You can even refer to a specific column in a row (that is, to a specific stack cell) by using the stack name as a qualifier:
CustNames(3).LastName
If you omit the row subscript, the position defaults to the first row. For example,
CustNames.LastName
is equivalent to
CustNames(1).LastName
Maintain Data provides two system variables associated with each stack. These variables help you to navigate through a stack and to manipulate single rows and ranges of rows:
- FocCount. This
value of the variable is always the number of rows currently in
the stack and is set automatically by Maintain Data. This is very
helpful when you loop through a stack, as described in the following
section, Looping Through a
Stack. FocCount is also helpful for checking if a stack is
empty:
IF CustNames.FocCount EQ 0 THEN PERFORM NoData;
- FocIndex. This
variable points to the current row of the stack. When a stack is
displayed in a form, the form sets FocIndex to the row currently
selected in the grid or browser. Outside of a form, the developer
sets the value of FocIndex. By changing its value, you can point
to any row you wish. For example, in one function you can increment
FocIndex for the Rental stack:
IF Rental.FocIndex LT Rental.FocCount THEN COMPUTE Rental.FocIndex = Rental.FocIndex + 1;
You can then invoke a second function that uses FocIndex to retrieve desired records into the MovieList stack:
FOR ALL NEXT CustID MovieCode INTO MovieList WHERE VideoTrk.CustID EQ Rental(Rental.FocIndex).CustID;
The syntax "stackname(stackname.FocIndex)" is identical to "stackname() ", so you can code the previous WHERE phrase more simply as follows:
WHERE VideoTrk.CustID EQ Rental().CustID
Looping Through a Stack
The REPEAT command enables you to loop through a stack. You can control the process in different ways, so that you can loop according to several factors:
- The number of times specified by a literal, or by the value of a field or expression.
- The number of rows in a stack, by specifying the FocCount variable of the stack.
- While an expression is true.
- Until an expression is true.
- Until the logic within the loop determines that the loop should be exited.
You can also increment counters as part of the loop.
Example: Using REPEAT to Loop Through a Stack
The following REPEAT command loops through the Pay stack once for each row in the stack and increments the temporary variable Row by one for each loop:
REPEAT Pay.FocCount Row/I4=1;
COMPUTE Pay(Row).NewSal = Pay(Row).Curr_Sal * 1.10;
ENDREPEAT Row=Row+1;Sorting a Stack
You can sort the row of a stack using the STACK SORT command. You can sort the stack by one or more of its columns and sort each column in ascending or descending order. For example, the following STACK SORT command sorts the CustNames stack by the LastName column in ascending order (the default order):
STACK SORT CustNames BY LastName
Editing and Viewing Stack Values
There are multiple ways in which you can edit and/or view the values of a stack.
- Forms. You can display a stack in an HTML table or a grid on a form. A grid enables you to edit the fields of a stack directly on the screen. You cannot edit a stack in an HTML table.
- COMPUTE command. You
can use the COMPUTE command to assign a value to any of the cells
of a stack. When assigning a value, the COMPUTE keyword is optional,
as described in Command Reference in
the Maintain Data Language Reference manual. For example,
the following command assigns the value 35000 to the cell at the
intersection of row 7 and column NewSal in the Pay stack:
COMPUTE Pay(7).NewSal = 35000;
It is important to note that if you do not specify a row when you assign values to a stack, Maintain Data defaults to the first row. Thus, if the Pay stack has 15 rows and you issue the following command
COMPUTE Pay.NewSal = 28000;
the first row receives the value 28000. If you issue this NEXT command
FOR 6 NEXT NewSal INTO Pay;
the current row of Pay defaults to one, and so the six new values are written to rows one through six of Pay. Any values originally in the first six rows of Pay will be overwritten.
If you wish to append the new values to Pay, that is, to add them as new rows 16 through 21, you would issue this NEXT command, which specifies the starting row:
FOR 6 NEXT NewSal INTO Pay(16);
You can accomplish the same thing without needing to know the number of the last row by of the stack using the FocCount variable:
FOR 6 NEXT NewSal INTO Pay(Pay.FocCount+1);
If you want to discard the original contents of Pay and substitute the new values, it is best to clear the stack before writing to it using the following command:
STACK CLEAR Pay; FOR 6 NEXT NewSal INTO Pay;
Default Data Source Stack: The Current Area
For all data source fields referenced by a Maintain Data procedure, Maintain Data creates a corresponding column in the default data source stack known as the Current Area.
The Current Area is always present and is global to the procedure. It has one row, and functions as a kind of data source buffer. Each data source field, that is, each field described in a Master File that is accessed by a Maintain Data procedure, has a corresponding column in the Current Area. When a data source command assigns a value, either to a field using INCLUDE, UPDATE, or REVISE, or from a field to a stack using NEXT or MATCH, Maintain Data automatically assigns that same value to the corresponding column in the single row of the Current Area. If a set-based data source command writes multiple values to or from a stack column, the last value that the command writes is the one that is retained in the Current Area.
Note: Stacks are a superior way of manipulating data source values. Since the Current Area is a buffer, it does not function as intuitively as stacks do. It is recommended that you use stacks instead of the Current Area to manipulate data source values.
For example, if you write 15 values of NewSal to the Pay stack, the values will also be written to the NewSal column in the Current Area; since the Current Area has only one row, its value will be the fifteenth (that is, the last) value written to the Pay stack.
The Current Area is the default stack for all FROM and INTO phrases in Maintain Data commands. If you do not specify a FROM stack, the values come from the single row in the Current Area. If you do not specify an INTO stack, the values are written to the single row of the Current Area, so that only the last value written remains.
The standard way of referring to a stack column is by qualifying it with the stack name and a period:
stackname.columnname
Because the Current Area is the default stack, you can explicitly reference its columns without the stack name, by prefixing the column name with a period:
.columnname
Within the context of a WHERE phrase, an unqualified name refers to a data source field (in a NEXT command) or a stack column (in a COPY command). To refer to a Current Area column in a WHERE phrase you should reference it explicitly by qualifying it with a period. Outside of a WHERE phrase it is not necessary to prefix the name of a Current Area column with a period, as unqualified field names will default to the corresponding column in the Current Area.
For example, the following NEXT command compares Emp_ID values taken from the Employee data source with the Emp_ID value in the Current Area:
FOR ALL NEXT Emp_ID Pay_Date Ded_Code INTO PayStack WHERE Employee.Emp_ID EQ .Emp_ID;
If the Current Area contains columns for fields with the same field name but located in different segments or data sources, you can distinguish between the columns by qualifying each one with the name of the Master File and/or segment in which the field is located:
masterfile_name.segment_name.column_name
If a user-defined variable and a data source field have the same name, you can qualify the name of the Current Area column of the data source field with its Master File and/or segment name; an unqualified reference will refer to the user-defined variable.
Maximizing Data Source Stack Performance
When you use data source stacks, there are several things you can do to optimize performance:
- Filter out unnecessary rows. When you read records into a stack, you can prevent the stack from growing unnecessarily large by using the WHERE phrase to filter out unneeded rows.
- Clear stacks when done with data. Maintain Data automatically releases a stack memory at the end of a procedure, but if in the middle of a procedure you no longer need the data stored in a stack, you can clear it immediately by issuing the STACK CLEAR command. Clearing the data frees the stack memory for use elsewhere.
- Do not reuse a stack for an unrelated purpose. When you specify a stack as a data source or destination in certain contexts (in the NEXT, MATCH, and INFER commands, and in the HTML canvas for controls), you define the columns that the stack will contain. If you use the same stack for two unrelated purposes, it will be created with the columns needed for both, making it unnecessarily wide.
| WebFOCUS | |
|
Feedback |