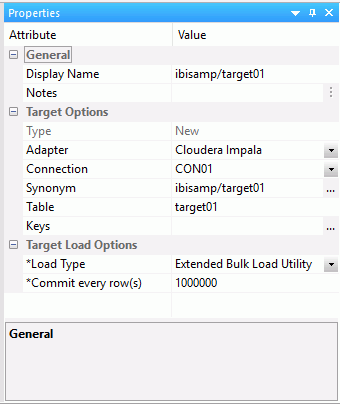
Loading Data Using DataMigrator
DataMigrator can be used to load data from any accessible data source into Hadoop and create metadata in Hive. Currently, the only load type supported is Extended Bulk Load.
To use DataMigrator to load data to Hadoop for access through Impala, we recommend that you install the DataMigrator Server on an Edge Node of your CDH cluster that has the Hadoop client software installed.If not, you can still use DataMigrator, but you must add the Fixed File adapter with the same name as the Impala adapter with an [S} FTP connection to a server where the Hadoop client is installed.
| WebFOCUS | |
|
Feedback |