Enabling the Database for Logging in Relational Databases
To use Change Data Capture, the source database must be configured to use database logging. In most organizations this must be done by a database administrator.
This example uses dminv as the source table. To create this table, see How to Create Sample Procedures and Data.
The database table must be enabled for logging, and the procedure depends on the database being used.
Configuring CDC in Microsoft SQL Server
Microsoft SQL Server supports Change Data Capture in the Enterprise, Evaluation, and Developer editions.
To use logging, the source database must be configured to use database logging. In most organizations, this must be done by a database administrator.
Logging must be enabled at the database level since it is disabled by default. The database table must be enabled for logging as well. To enable logging, you must be connected as a member of the sysadmin server role.
To enable logging on a database level, connect to the database you want to enable and issue the following commands:
exec sys.sp_cdc_enable_db select name, is_cdc_enabled from sys.databases
You will see a list of all databases and a 1 if logging is enabled for the database, or a 0 otherwise.
To check if the SQL Server Agent is running, open the Microsoft SQL Server Management Studio and navigate to the Object Explorer window. Click the icon for SQL Server Agent. It should have a green arrow. If it does not, right-click SQL Server Agent and click Start.
The SQL Server Agent and two jobs must be running. The jobs are created automatically when the database is enabled. For example, if the database is called main, the jobs would be named cdc.main_capture and cdc.main_cleanup.
After the SQL Server job Cleanup completes, the content of the current SQL Server transaction log changes. If the checkpoint file created by DataMigrator contains the LSN value, which is not within a Validity Interval of the retained transaction log, the Adapter setting LOG_SWITCHED is taken into account.
The Adapter setting LOG_SWITCHED is located on the Change Setting screen:
ENGINE engine SET LOG_SWITCHED { STOP | PROCEED }The default value is STOP.
For more information on the checkpoint file, see Creating a DataMigrator Direct Load Flow.
In some situations, the updates on the database occur and the Cleanup job runs, but the DataMigrator flow is not running after the Cleanup job. In this case, the Validity Interval on the database might not have the LSN value that is matching the LSN in the checkpoint file.
When the value of the LOG_SWITCHED is set to STOP and the LSN value in the checkpoint file is not within a Validity Interval of the retained transaction log, the CDC flow returns the following error:
(FOC45008) INVALID CHECKPOINT
The checkpoint file is not updated at this point.
Note: To continue the successful flow execution, delete the existing checkpoint file.
When the value of the LOG_SWITCHED setting is set to PROCEED and the LSN value in the checkpoint file is not within a Validity Interval on the database, the CDC flow proceeds and updates the checkpoint file.
Note: In this situation, the change data values could be not updated by a flow as missing in the Validity Interval.
Each table to be used must have CDC enabled. This can be done from Microsoft SQL Server Management Studio. You must be a member of the db_owner database role to run the stored procedure. Issue the following commands, where tablename is the name of the table.
exec sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'tablename', @role_name = NULL select is_tracked_by_cdc FROM sys.tables WHERE name = 'tablename'
Example:
exec sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'dminv', @role_name = NULL select is_tracked_by_cdc FROM sys.tables WHERE name = 'dminv'
You will see a 1 if the table is enabled, and a 0 otherwise.
Configuring CDC in MySQL
|
Topics: |
MySQL supports Change Data Capture.
Preparing the Environment for CDC with MySQL
In order to use CDC with MySQL, you must install Java and MySQL client utilities on the system where the DataMigrator Server is installed. Additionally, on that system, you must have the Environment Variable CLASSPATH pointing to the location where the Connector/J is installed. Note that the location of Connector/J itself can be anywhere on your system. For complete documentation on configuring data adapters for MySQL, see the Adapter Administration manual.
Java
To use CDC with the MySQL adapter, you must have Java installed. The system Environment Variables JAVA_HOME or JDK_HOME must be specified, and the location of Java must be added to the PATH Environment Variable.
For example, if your DataMigrator Server is on Linux, add the following lines to your profile:
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0_91 export JDK_HOME=/usr/lib/jvm/jdk-1.8.0_91 export PATH=$JAVA_HOME/bin:$PATH
Connector/J
Connector/J is an interface that provides MySQL support for Java client programs that use JDBC connections. Connector/J is a JAR file with a standard name of mysql-connector-java-version-bin.jar. The file can be installed on any system on your environment.
The location of the Connector/J must be specified in either the Environment Variable CLASSPATH on the same system where DataMigrator is installed, or in a IBI_CLASSPATH variable of a DataMigrator Server. To specify the location of the Connector/J in the IBI_CLASSPATH variable of a DataMigrator Server, perform the following steps:
- In the DMC, expand Workspace and expand the Java Services folder.
- Right-click DEFAULT and select Properties.
The Java Services Configuration pane opens.
- Expand the Class path section.
- In the IBI_CLASSPATH field, specify the full path file name to the MySQL Connector J JAR file.
- Click Save and Restart Java Services.
Utilities for Processing Binary Log Files
While the MySQL database does not have to be installed on the same system where DataMigrator server installed, the MySQL client utilities for processing binary log files, mysql and mysqlbinlog, must be placed into a directory on the same system where DataMigrator is installed.
The version of these MySQL client utilities must be the same as the version of the MySQL database. The Environmental Variable PATH should list the path to the directory where the MySQL client utilities are placed.
The maximum size of the binary log files is set in the max_binlog_size system variable, and has a maximum possible value of 1 GB. The Binary Log is flushed when its size reaches its maximum, 1 GB. As a general rule, avoid using the LONGTEXT data type in a table that is used for CDC operations, as this data type has large storage requirements.
Configuring MySQL
MySQL enables logging at the database level by storing the history of database changes in the Binary Log Files. These Binary Log Files are used by DataMigrator for CDC operations and must use row-based logging. For example:
--binlog-format=ROW
Although it is possible to change the logging format at runtime, the best practice is to set it at a database server startup.
A user ID assigned on a connection to a MySQL database must have either a SUPER privilege or three global privileges: REPLICATION CLIENT, REPLICATION SLAVE, and SELECT. This task is typically performed by a database administrator. One method to assign such privileges is to issue the SQL statements shown in the following examples:
To create user1 on any host:
CREATE USER 'user1'@'%' IDENTIFIED BY ‘password1’;
To grant user1 all privileges:
GRANT ALL PRIVILEGES ON *.* TO 'user1'@'%' IDENTIFIED BY 'password1';
To enable user1 for reading the binary logs from any subordinate host:
GRANT REPLICATION CLIENT ON *.* TO 'user1'@'%' IDENTIFIED BY 'password1';
To enable user1 for reading the binary logs from any master host:
GRANT REPLICATION SLAVE ON *.* TO 'user1'@'%' IDENTIFIED BY 'password1';
To enable user1 for selecting all objects in a database named dbname1:
GRANT SELECT ON dbname1.* TO 'user1'@'%' IDENTIFIED BY 'password1';
Configuring CDC in Oracle
Configuring ORACLE for Change Data Capture can be done from Oracle SQL Developer or SQL Plus. In most organizations, this must be done by a database administrator.
connect sys/* as sysdba
To use the Change Data Capture, the database must be configured to use archiving. Enter the command:
ALTER SYSTEM ARCHIVE LOG START;
When using ORACLE XE (Express Edition), enter the following commands instead:
SHUTDOWN IMMEDIATE STARTUP MOUNT ALTER DATABASE ARCHIVELOG; ALTER DATABASE OPEN;
Confirm that archive log is enabled with the command:
select log_mode from v$database;
You should see the following result:
LOG_MODE ------------ ARCHIVELOG
To retrieve log information, a user ID needs to access certain system tables through public views. Issue these commands, where userid represents the user ID running CDC jobs.
grant select on "SYS"."V_$LOG" to userid ; grant select on "SYS"."V_$LOGMNR_CONTENTS" to userid ; grant select on "SYS"."V_$DATABASE" to userid;
To enable logging, a user ID must be granted the following, where userid represents the user ID to be used.
GRANT EXECUTE ON dbms_logmnr TO userid; GRANT SELECT ANY TRANSACTION TO userid;
The table being logged must have all data columns logged by issuing the following command, where tablename represents the table to be logged.
ALTER TABLE tablename ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Add supplemental log information for the database by entering:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
You can confirm that supplemental logging is enabled for a table with the following command. It should show YES.
select distinct b.owner , b.object_name, supplemental_log_data_min from v$database a, sys.all_objects b where b.owner = 'userid' and b.object_name = 'tablename'
Note: If you recreate a database table, you must re-issue this command.
Change Data Capture for Oracle uses the DBMS_LOGMNR package to extract values from the Oracle redo log files. This does not support the following data types:
- LONG
- LONG RAW
- CLOB
- BLOB
- NCLOB
- ADT
- COLLECTION
Configuring CDC in IBM Db2 Universal Database on Windows and UNIX
Note that CDC support for UDB and Db2 requires the CLI interface. To enable the database for logging, issue the following commands from the Db2 command center:
UPDATE DATABASE CFG FOR database USING DFT_SQLMATHWARN YES UPDATE DATABASE CFG FOR database USING LOGARCHMETH1 LOGRETAIN UPDATE DBM CFG USING DISCOVER DISABLE UPDATE DBM CFG USING DISCOVER_INST DISABLE GRANT DBADM ON database TO USER userid
The Db2 table must have capture mode enabled. This can be done from the Db2 Command Center or a stored procedure.
In order to use Change Data Capture, each table must have data changes written to the log in an expanded format. Enter the following command, where tablename is the name of the table:
ALTER TABLE tablename DATA CAPTURE CHANGES
To return a table back to normal logging, use the following command:
ALTER TABLE tablename DATA CAPTURE NONE
SELECT CREATOR, NAME, TYPE FROM SYSIBM.SYSTABLES WHERE DATA_CAPTURE = 'Y'
Configuring CDC in IBM Db2 Universal Database on System Z
Note: CDC support for UDB and Db2 requires the CLI interface.
To enable the database for logging, issue the following Db2 commands:
UPDATE DATABASE CFG FOR database USING DFT_SQLMATHWARN YES UPDATE DATABASE CFG FOR database USING LOGARCHMETH1 LOGRETAIN UPDATE DBM CFG USING DISCOVER DISABLE UPDATE DBM CFG USING DISCOVER_INST DISABLE GRANT DBADM ON database TO USER userid
In order to use Change Data Capture, each table must have data changes written to the log in an expanded format. Enter the following command, where tablename is the name of the table:
ALTER TABLE tablename DATA CAPTURE CHANGES
To return a table back to normal logging, use the following command:
ALTER TABLE tablename DATA CAPTURE NONE
SELECT CREATOR, NAME, TYPE FROM SYSIBM.SYSTABLES WHERE DATACAPTURE = 'Y'
Configuring CDC in IBM Db2 Universal Database on iSeries
|
Topics: |
- The prerequisite requirement for CDC with Db2 on iSeries (IBM i) is to assign the value *MAXOPT3 to attribute RCVSIZOPT (receiver size options) at the initial stage, when the journal is
created. Example commands are:
CRTJRN JRN(LIBRARY1/JRNLB) JRNRCV(LIBRARY1/RCV01) RCVSIZOPT(*MAXOPT3 *RMVINTENT)
When the journal receiver is changed, the new receiver gets a new (LSN) sequence number. Assign the *CONT value to the SEQOPT attribute to allow your journal entry sequence number to continue in the subsequent receivers. For example:
CHGJRN JRN(LIB71M1/QSQJRN) JRNRCV(*GEN) RCVSIZOPT(*RMVINTENT *MAXOPT3) SEQOPT(*CONT)
- The name of the journaling Db2 table on iSeries (IBM i) must not exceed 10 characters. To process DELETE records, make sure that the *BOTH (before-images and after-images) value has been set for the journal IMAGES parameter.
- The name of the journaling Db2 table on IBM i must not exceed 10 characters. To process DELETE records, make sure that the *BOTH (before-images and after-images) value has been set for the journal IMAGES parameter.
- Note: Your flow retrieves the journal entries that are presently available, regardless of the journal state. To ensure that your flow gets the most current updates from the journal entries, verify that your journal is in the *ACTIVE state.
The following setting for the Db2 adapter on IBM i allows processing of the 'before-images' (UB type) journal records (additionally to the 'after-images'), and helps with the updates of the target table of the flow if the keys fields on a source table had been changed:
ENGINE DB2 CDC_UPDATE_BEFORE_IMAGE {OFF | ON}The default value for this setting is OFF.
The setting can be used on either a Server level or a flow level. To use the setting on the server level, use one of the following two methods:
- Use the following command in a server profile edasprof:
ENGINE DB2 CDC_UPDATE_BEFORE_IMAGE ON
- From the DMC or the Web Console, expand the Adapters folder. Right-click the name of the adapter you want to configure and click Change Settings. From the Change Settings dialog box, in the Metadata section, select ON from the CDC_UPDATE_BEFORE_IMAGE drop-down menu.
Note: Once saved in the server profile edasprof, the setting will be applied globally.
To apply the setting on a flow level, use the following command in a WebFOCUS procedure:
ENGINE DB2 CDC_UPDATE_BEFORE_IMAGE ON
Attach the procedure on a Process flow in front of a Data flow.
Journaling for an iSeries (IBM i) library can happen in one of three ways:
- The library is initially created by Db2 with the CREATE COLLECTION collection-name or CREATE SCHEMA schema-name command, which creates the library itself, catalogs resources with the library and standard journal resources within the library, and turns on the journaling. The CREATE SCHEMA and CREATE COLLECTION commands are synonyms for each other, and there are no differences in their actual functions.
- Add journal resources to an existing not journaling library and turn them on, effectively turning it into a Journal Library. This option also allows for non-standard names to be used in the journaling.
- Add a QDFTJRN Data Area to an existing not journaling library. This effectively redirects journaling to happen in an alternate library (that already has journaling enabled). Thus, the not journaling library becomes a Journal Library with journals elsewhere.
Starting from release 7.7.08M a flow or a report that uses a synonym for Table Log Records will not fail with error anymore when a sequence discrepancies happens on a journal.
Note: If the journal contains a very large number of records, to take an advantage of new functionality which handles the large RRN on a journal, the user needs to re-create the synonyms for the Table Log Records.
These three items are described in the following sections.
Creating a Journal Library
Start the System i Main Menu screen with the user ID that will be used to run the CDC flows.
To start Structured Query Language interface, type:
STRSQL
To create a collection, type:
CREATE COLLECTION LIBRARY1
To create the Db2 table TABLE1 in the library LIBRARY1, type:
CREATE TABLE LIBRARY1/TABLE1(F1 INT, F2 CHAR (10 ))
To insert a row into TABLE1, type:
INSERT INTO TABLE1 VALUES (1,'Rec 1 t1')
To exit the Structured Query Language interface, press the functional key [PF3].
Turning a Library Into a Journaling Library
Note: Minimized journal entries are not supported by DataMigrator. Therefore, the MINENTDTA parameter in the command CRTJRN (or CHGJRN) should not be specified. If it must be specified, this parameter should use an attribute of *NONE.
To turn a library into a journaling library, use the following commands:
To create a library called LIBRARY2, type:
CRTLIB LIBRARY2
To create a journal receiver called QSQJRN0001 for the library LIBRARY2, type:
CRTJRNRCV JRNRCV(LIBRARY2/QSQJRN0001)
To create a journal QSQJRN in the library LIBRARY2, with journal receiver QSQJRN0001, type:
CRTJRN JRN(LIBRARY2/QSQJRN) JRNRCV(LIBRARY2/QSQJRN0001)
To start Commitment Control with a lock level for ALL with default journal QSQJRN in library LIBRARY2, type:
STRCMTCTL LCKLVL(*ALL) DFTJRN(LIBRARY2/QSQJRN)
To change current library to LIBRARY2, type:
CHGCURLIB LIBRARY2
To start Structured Query Language interface, type:
STRSQL
To create the Db2 table TABLE2 in the library LIBRARY2, type:
CREATE TABLE LIBRARY2/TABLE2(F1 INT, F2 CHAR (10 ))
To insert a row into TABLE2, type:
INSERT INTO TABLE2 VALUES (1, ‘Rec 1 t2’)
To exit the Structured Query Language interface, press the Functional key [PF3].
To ensure journaling (to turn it ON) by adding a not journaling, pre-existing Db2 table, TABLE2, to an existing Journal Library, type:
STRJRNPF FILE(LIBRARY2/TABLE2) JRN(LIBRARY2/QSQJRN)
As a result of this statement, the following message appears: “Object of type *FILE already being journaled”.
Note: Journaling can be turned on and off for individual files with the STRJRNPF and ENDJRNPF commands.
At this point, the table TABLE2 is log enabled, which means that journaling works for this table. You can proceed to DataMigrator, creating the Table Log Records synonym for this table and CDC flows.
Enabling Journaling on a Not Journaling Library
There might be situations when you need to keep a table or tables in one library, and the journaling in a different library. In order to get these results, the not journaling library should get connected to a Journal library.
The following names will be used for the objects in the examples below:
- LIBRARY1 is the Journal Library that was created in Creating a Journal Library, above.
- QDFTJRN is a data area, which must exist in the LIBRARY3.
To create a library called LIBRARY3, type:
CRTLIB LIBRARY3
To Create a QDFTJRN data area in the not journaling library and have LIBRARY3 point to the Journal Library LIBRARY1, type:
CRTDTAARA DTAARA(LIBRARY3/QDFTJRN) TYPE(*CHAR) LEN(25)
VALUE('LIBRARY1 QSQJRN *FILE')As a result of this, the following statement message appears: “Data area QDFTJRN created in library LIBRARY3”.
Note: VALUE() is a fixed position string with schema starting in position 1, journal name in position 11 and *FILE in position 21. In other words, VALUE('SSSSSSSSSSJJJJJJJJJJ*FILE') with blank padding for names less than 10.
To change the current library to the library LIBRARY2 and display the properties of that library, type:
CHGCURLIB LIBRARY3
To start the Structured Query Language interface, type:
STRSQL
To create the Db2 table TABLE1 in the library LIBRARY2, type:
CREATE TABLE LIBRARY3/TABLE3(F1 INT, F2 CHAR (10 ))
To insert a row into TABLE1, type:
INSERT INTO TABLE3 VALUES (1, ‘Rec 1 t3’)
To exit the Structured Query Language interface, press the Functional key [PF3].
List of Optional Commands
Change the current library to the schema you have created with following command:
CHGCURLIB LIBRARY1
To change user profile, type:
CHGPRF CURLIB(LIBRARY1)
All tables that are created within this COLLECTION are being journaled. In other words, all the tables in this library have journals and Change Data Capture enabled for them.
You can confirm the current schema by issuing the command:
DSPLIBL
The result of this command should resemble the following image:
To review the current library, type:
DSPLIBL
Scroll down the pages to view the journaling information.
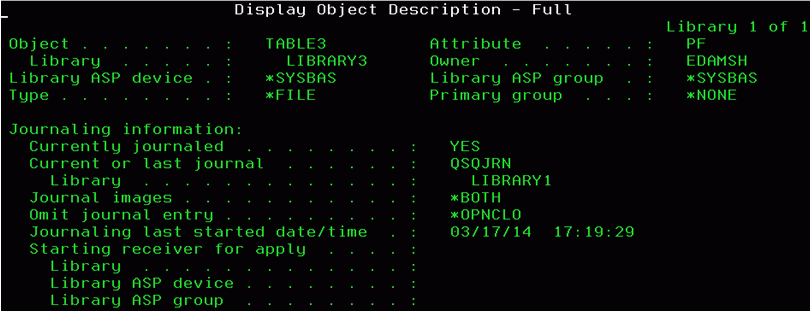
Please observe the attributes of the table TABLE3, and notice that it is located in the library LIBRARY3, yet its current journal is QSQJRN which belongs to the library LIBRARY1.
Configuring CDC in IBM Db2 Universal Database on z/OS
Note: CDC support for UDB and Db2 requires the CLI interface.
The configuration file DSNAOINI (*.ini file) should contain the proper value for the MVSATTACHTYPE attribute. This configuration file should contain either:
MVSATTACHTYPE=CAF
or
MVSATTACHTYPE=RRSAF MULTICONTEXT=0
Review the user ID that is specified in the DataMigrator connection for the Db2 adapter. This user ID needs to have SYSADM authority and an authority for monitoring Db2 logs. The latter implies that the system table SYSIBM.SYSUSERAUTH should contain the values for the MON1AUTH and MON2AUTH fields set to Y.
To ensure that data changes are written to the log, enabling Change Data Capture for a table, enter the following Db2 commands, where tablename is the name of the table to be log enabled.
ALTER TABLE tablename DATA CAPTURE CHANGES COMMIT WORK; GRANT ALL ON tablename TO PUBLIC; COMMIT WORK;
To verify that the tables have the logging enabled, issue the following Db2 select statement:
SELECT CREATOR, NAME, TYPE FROM SYSIBM.SYSTABLES WHERE NAME LIKE '%tablename%' AND TYPE IN( 'T','P');
Configuring CDC in MariaDB
|
Topics: |
MariaDB supports Change Data Capture.
Preparing the Environment for CDC with MariaDB
In order to use CDC with MariaDB, you must install Java, Connector/J, and the MariaDB client utilities. All of these components must be installed on the same system where the DataMigrator Server is installed. For complete documentation on configuring data adapters for MariaDB, see the Adapter Administration manual.
Java
To use CDC with the MariaDB adapter, you must have Java installed. The system Environment Variables JAVA_HOME and JDK_HOME must be specified and the location of Java must be added to the PATH Environment Variable.
For example, if your DataMigrator Server is on Linux, add the following lines to your profile:
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0_91 export JDK_HOME=/usr/lib/jvm/jdk-1.8.0_91 export PATH=$JAVA_HOME /bin:$PATH
Connector/J
Connector/J is an interface that provides MariaDB support for Java client programs that use JDBC connections. Connector/J is a JAR file. MariaDB Connector/J .jar files are available at https://downloads.mariadb.org/connector-java/.
After you download the .jar file, the location of the Connector/J must be specified in either the Environment Variable CLASSPATH on the same system where DataMigrator is installed, or in a IBI_CLASSPATH variable of a DataMigrator Server. To specify the location of the Connector/J in the IBI_CLASSPATH variable of a DataMigrator Server, perform the following steps:
- In the DMC, expand Workspace and expand the Java Services folder.
- Right-click DEFAULT and select Properties.
The Java Services Configuration pane opens.
- Expand the Class path section.
- In the IBI_CLASSPATH field, specify the full path file name to the MariaDB Connector J JAR file.
- Click Save and Restart Java Services.
Utilities for Processing Binary Log Files
While the MariaDB database does not have to be installed on the same system where the DataMigrator Server is installed, the MariaDB client utilities for processing binary log files, mysql and mysqlbinlog, must be placed into a directory on the same system where DataMigrator is installed.
The version of these MariaDB client utilities must be the same as the version of the MariaDB database. The Environmental Variable PATH should list the path to the directory where the MariaDB client utilities are placed.
The maximum size of the binary log files is set in the max_binlog_size system variable, and has a maximum possible value of 1 GB. The Binary Log is flushed when its size reaches its maximum, 1 GB. As a general rule, avoid using the LONGTEXT data type in a table that is used for CDC operations as this data type has large storage requirements.
Configuring MariaDB
MariaDB enables logging at the database level by storing the history of database changes in the Binary Log Files. These Binary Log Files are used by DataMigrator for CDC operations and must use row-based logging. For example:
--binlog-format=ROW
Although it is possible to change the logging format at runtime, the best practice is to set it at the database server startup.
A user ID assigned on a connection to a MariaDB database must have either a SUPER privilege or three global privileges: REPLICATION CLIENT, REPLICATION SLAVE, and SELECT. This task is typically performed by a database administrator. One method to assign such privileges is to issue the SQL statements shown in the following examples.
To create user1 on any host:
CREATE USER 'user1'@'%' IDENTIFIED BY ‘password1’;
To grant user1 all privileges:
GRANT ALL PRIVILEGES ON *.* TO 'user1'@'%' IDENTIFIED BY 'password1';
To enable user1 for reading the binary logs from any subordinate host:
GRANT REPLICATION CLIENT ON *.* TO 'user1'@'%' IDENTIFIED BY 'password1';
To enable user1 for reading the binary logs from any master host:
GRANT REPLICATION SLAVE ON *.* TO 'user1'@'%' IDENTIFIED BY 'password1';
To enable user1 for selecting all objects in a database named dbname1:
GRANT SELECT ON dbname1.* TO 'user1'@'%' IDENTIFIED BY 'password1';
| WebFOCUS | |
|
Feedback |