SQL Adapters
This section provides detailed descriptions of new features for SQL adapters.
All SQL Adapters
This section provides detailed descriptions of new features for all SQL adapters.
Optimization of Simplified Numeric Functions
The following new simplified numeric functions are optimized by the SQL adapters:
- CEILING. Returns the smallest integer value greater than or equal to a value.
- EXPONENT. Raises the constant e to a power.
- FLOOR. Returns the largest integer less than or equal to a value.
- MOD. Calculates the remainder from a division.
- POWER. Raises a value to a power.
Optimization of Simplified Functions REPLACE, TOKEN, and POSITION
The following simplified character functions are optimized by the SQL adapters.
- REPLACE. Replaces all instances of a string.
- TOKEN. Extracts a token (substring) from a string.
- POSITION. Returns the first position of a substring.
Enhancement to the Optimization of LIKE for Fixed Length Fields
In prior releases, the LIKE operator was not optimized for those RDBMS engines (such as Db2) that count trailing blanks when comparing columns because the FOCUS LIKE operator is not sensitive to trailing blanks. Now, LIKE is optimized by removing trailing blanks in the SQL passed to those RDBMS engines using the RTRIM function. (RTRIM(column) LIKE mask).
LIKE optimization works as long as the mask does not end with an underscore character (_). Optimization does work when the mask starts or ends with a percent sign (%).
Example: Optimizing the LIKE Operator for Fixed Length Fields
The following request creates a fixed-length field named CATEGORY and uses it in a WHERE test with the LIKE operator.
SET TRACEUSER=ON
SET TRACEON=STMTRACE//CLIENT
SET TRACESTAMP=OFF
DEFINE FILE WF_RETAIL_LITE
CATEGORY/A10 = PRODUCT_SUBCATEG;
END
TABLE FILE WF_RETAIL_LITE
SUM COGS_US
BY CATEGORY
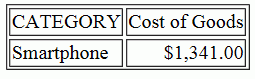
WHERE CATEGORY LIKE '%phone'
ON TABLE SET PAGE NOLEAD
ENDThe following SQL is generated, which trims trailing blanks from the CATEGORY column.
AGGREGATION DONE ...
SELECT
T7."PRODUCT_SUBCATEG",
SUM(T1."COGS_US")
FROM
D999OL29_wf_retail_sales T1,
D999OL29_wf_retail_product T7
WHERE
(T7."ID_PRODUCT" = T1."ID_PRODUCT") AND
(TRIM(TRAILING ' ' FROM T7."PRODUCT_SUBCATEG") LIKE '%phone')
GROUP BY
T7."PRODUCT_SUBCATEG"
ORDER BY
T7."PRODUCT_SUBCATEG"
FOR FETCH ONLY; The output is shown in the following image.
PERSISTENCE Option for HOLD FORMAT sqlengine
The PERSISTENCE option has been added to the HOLD command when it is used to create an SQL table.
This new command option allows you to generate intermediate tables of different types that will be used only during UPLOAD and EBL requests to accelerate performance by keeping all processing on the DBMS server instead of downloading data into a HOLD file. The actual type of the intermediate table will be determined at run time, based on specific DBMS-supported features and the data-populating mechanisms being used.
The syntax is:
HOLD FORMAT sqlengine PERSISTENCE {STAGE|PERMANENT}where:
- sqlengine
-
Identifies the relational DBMS in which to create the table.
- STAGE
-
Will create either a Volatile or GLOBAL TEMPORARY table, for a DBMS that supports that functionality, currently HP Vertica, Db2, Oracle, Teradata, MS SQL, and MySQL. For a DBMS that does not support that functionality, a message will display and the table will not be created.
- PERMANENT
- Will create a regular SQL table with a uniquely-generated name that will be used in the request and will be available for further use after the request ends, but will be dropped at the end of the session. This is the default value for PERSISTENCE for HOLD FORMAT sqlengine.
Optimizing a Heterogeneous Join for a Qualified DBMS
Joins, including outer joins, between segments that belong to different SQL engines now are eligible for SQL optimization. The SQL adapters will optimize a join for segments that belong to the same engine, and then intermediate results from each engine will be combined on the server into one resulting join.
Enhanced BY Clause Optimization
The relational adapters now optimize reports that contain a BY field more efficiently, by no longer passing MAX(field) in the SELECT list to the RDBMS.
Tutorials Now Created With Foreign Key Constraints
When creating Star Schema or Retail Demo tutorial tables from the Web Console or Data Management Console, the fact tables now have foreign key constraints for each of the dimension tables. This facilitates building a cluster join from these tools. It also prevents loading rows in the fact table without corresponding rows in the dimension tables.
For example, the following is the Access File for the wf_retail_labor fact table, which has a foreign key constraint for the wf_retail_employee table.
SEGNAME=WF_RETAIL_LABOR,
TABLENAME=wrd_wf_retail_labor,
CONNECTION=wfretail,
KEY=ID_LABOR, $
FOREIGN_KEY=fact_labor_id_employee_fk,
PRIMARY_KEY_TABLE=wrd_wf_retail_employee,
FOREIGN_KEY_COLUMN=ID_EMPLOYEE,
PRIMARY_KEY_COLUMN=ID_EMPLOYEE, $Creating Tutorials With Lowercase Column Names
Previously, column names for the tutorials were always created in uppercase. However, certain databases, such as PostgreSQL and those based on it For example, Greenplum) expects column names to be lowercase.
Now, when the adapter setting ALIAS_CASE is set to LOWER, tutorial column names will be lowercase.
Saving Adapter Settings in a Profile or Stored Procedure
When you customize SQL adapter settings by right-clicking an adapter and selecting Change Settings from the shortcut menu, the top of the page lets you select either Profile or Procedure from the Save settings in drop-down list, as shown in the following image.
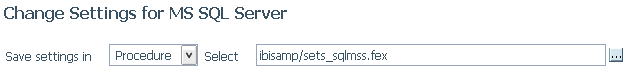
If you select Procedure, a procedure is automatically generated with the settings you changed. You can accept the default application and procedure name, or you can select a different application in which to store the procedure and enter a file name for the procedure.
The procedure can be added to a Process Flow, making you able to define flow-level settings rather than global settings using the Web Console.
Mapping Spatial Data Stored in RDBMS Columns
The Adapters for MS SQL Server, Oracle, Teradata, and MySQL now support direct read from DBMS spatial columns that store Esri data.
The Access File contains the expression needed to retrieve the spatial data, which is different for each DBMS. The geographic data is returned as a Geometry object that can be used to render maps in WebFOCUS GRAPH requests.
For example, in the Following SQL Server Master File, the field GEO contains spatial data representing geographic areas. In SQL Server, the data type for this field is GEOMETRY or GEOGRAPHY. In the Master File, it is mapped as text, with a GEOGRAPHIC_ROLE attribute.
FIELDNAME=GEO, ALIAS=GEO, USAGE=TX50, ACTUAL=TX,MISSING=ON, GEOGRAPHIC_ROLE=GEOMETRY_AREA, $
The following are the Access File attributes for this field.
IELD=GEO,
SQL_FLD_OBJ_TYPE=OPAQUE,
SQL_FLD_OBJ_PROP=GEOMETRY_SHAPE,
SQL_FLD_OBJ_EXPR='DB_EXPR("GEO".STGeometryType()
+ '',''
+ CAST( "GEO".STSrid AS VARCHAR(10) )
+ '',''
+ "GEO".STAsText())', $The following request retrieves the GEO field.
TABLE FILE EUROPE_SWASIA
PRINT NAME GEO
WHERE NAME IN ('FRANCE','GERMANY','UNITED KINGDOM')
ENDThe SQL passed to SQL Server as a result of this request follows.
SELECT
T1."NAME",
(T1."GEO".STGeometryType() + ',' + CAST(
T1."GEO".STSrid AS VARCHAR(10) ) + ',' +
T1."GEO".STAsText())
FROM
EUROPE_SWASIA T1
WHERE
(T1."NAME" IN ('FRANCE','GERMANY','UNITED KINGDOM');The following are sample Access File attributes for Oracle.
SQL_FLD_OBJ_EXPR='DB_EXPR(CASE "GEO".Get_GType()
WHEN 1 THEN ''Point''
WHEN 2 THEN ''LineString''
WHEN 3 THEN ''Polygon''
WHEN 4 THEN ''GeometryCollection''
WHEN 5 THEN ''MultiPoint''
WHEN 6 THEN ''MultiLineString''
WHEN 7 THEN ''MultiPolygon''
WHEN 8 THEN ''PolyhedralSurface''
ELSE ''Geometry'' END
|| '',''
|| CAST( "GEO".SDO_SRID AS VARCHAR(10) )
|| '',''
|| "GEO".Get_WKT())', $
--Teradata:
SQL_FLD_OBJ_EXPR='DB_EXPR(Substring("GEO".ST_GeometryType() From
4)
|| '',''
|| CAST( "GEO".ST_SRID() AS VARCHAR(10) )
|| '',''
|| "GEO".ST_AsText())', $Enhanced Messages About SQL Optimization
More descriptive messages have been developed when SQL Optimization is not done for a request. In some cases, a message will contain information about ways to possibly change the syntax so that optimization can be used.
Optimization of Function DTRUNC for First Day of Week
Calls to the DTRUNC function can be optimized when using the new WEEK parameter that returns the first day of the week in which the date occurs.
Optimization of Function DTRUNC for YEAR_END, QUARTER_END, MONTH_END and WEEK_END
Calls to the DTRUNC function can be optimized when using the new YEAR_END, QUARTER_END, MONTH_END and WEEK_END parameters that return the last day of the period in which the date occurs.
CONCAT Function Optimization
Simplified character function CONCAT is passed to the Relational Adapters in the generated SQL.
Optimization of the DT_CURRENT_DATE, DT_CURRENT_DATETIME, and DT_CURRENT_TIME Functions
The simplified functions DT_CURRENT_DATE, DT_CURRENT_DATETIME, and DT_CURRENT_TIME are passed to the Relational Adapters in the generated SQL request.
Example: Optimizing the DT_CURRENT_DATETIME Function
The following request calls the DT_CURRENT_DATETIME function.
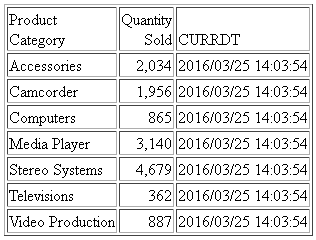
SET TRACEUSER=ON SET TRACEON=STMTRACE//CLIENT SET TRACESTAMP=OFF DEFINE FILE WF_RETAIL_LITE CURRDT/HYYMDS = DT_CURRENT_DATETIME(SECOND); END TABLE FILE WF_RETAIL_LITE SUM QUANTITY_SOLD CURRDT BY PRODUCT_CATEGORY ON TABLE SET PAGE NOLEAD END
The following SQL is generated for Microsoft SQL Server.
SELECT
T7."PRODUCT_CATEGORY",
SUM(T1."QUANTITY_SOLD"),
MAX(SYSDATETIME())
FROM
( wrd_wf_retail_sales T1
LEFT OUTER JOIN
wrd_wf_retail_product T7
ON T7."ID_PRODUCT" = T1."ID_PRODUCT" )
GROUP BY
T7."PRODUCT_CATEGORY"
ORDER BY
T7."PRODUCT_CATEGORY"; The output is shown in the following image.
SQL Adapters Support CREATE FILE With FOREIGNKEYS
|
How to: |
The CREATE FILE command now supports defining foreign key constraints to enforce referential integrity.
Syntax: How to Issue a CREATE FILE Command With Foreign Keys
CREATE FILE app/synonym [WITHFK [DROP]]
where:
- app/synonym
-
Is the synonym that describes the table to be created.
- DROP
-
Drops the table if it already exists and then creates it.
Application Access Control for HyperStage Tables
SQL Adapters Optimize Calls to the GIS_POINT Function in a DEFINE
Given a WKID (Well-Known ID) spatial reference, longitude, and latitude, the GIS_POINT function builds a JSON point defining a Geometry object with the provided WKID, longitude, and latitude. The function is optimized for those SQL engines that can build a JSON geometry object.
Example: Optimizing Calls to the GIS_POINT Function
The following request calls the GIS_POINT function in a DEFINE command. Note that the field WKID is defined in the WF_RETAIL_LITE Master File.
SET TRACEUSER=ON SET TRACEON = STMTRACE//CLIENT SET TRACESTAMP=OFF DEFINE FILE wf_retail_lite Point/A150 MISSING ON ALL=GIS_POINT(WKID, CONTINENT_LONGITUDE, CONTINENT_LATITUDE); END TABLE FILE wf_retail_lite PRINT Point BY WF_RETAIL_GEOGRAPHY_STORE.CONTINENT_CODE AS 'Continent Code' ON TABLE SET PAGE NOLEAD END
The following SQL is generated.
SELECT T1."ID_STORE", T1."ID_CUSTOMER", T2."ID_GEOGRAPHY", T3."ID_GEOGRAPHY", T3."CONTINENT_LATITUDE", T3."CONTINENT_LONGITUDE", T5."ID_GEOGRAPHY", T6."ID_GEOGRAPHY", T6."CONTINENT_CODE" FROM ( ( ( ( wrd_wf_retail_sales T1 INNER JOIN wrd_wf_retail_customer T2 ON (T2."ID_CUSTOMER" = T1."ID_CUSTOMER") ) LEFT OUTER JOIN wrd_wf_retail_geography T3 ON T3."ID_GEOGRAPHY" = T2."ID_GEOGRAPHY" ) INNER JOIN wrd_wf_retail_store T5 ON (T5."ID_STORE" = T1."ID_STORE") ) LEFT OUTER JOIN wrd_wf_retail_geography T6 ON T6."ID_GEOGRAPHY" = T5."ID_GEOGRAPHY" ) ORDER BY T6."CONTINENT_CODE";
The partial output is shown in the following image.

Enhanced Optimization of Selection Tests
In prior releases, all optimized selection tests were passed to the RDBMS and also re-evaluated when the answer set was returned to FOCUS. Starting in this release, individual tests passed to the SQL engines may be excluded from execution. This enhances performance and also allows tests to be optimized that are not totally compatible with how FOCUS evaluates them.
Optimization of the PARTITION_REF Function
Calls to the PARTITION_REF function in an aggregation request with a WHERE TOTAL phrase can be passed to SQL engines that have a LAG function, such as Db2, Oracle, Teradata, and Microsoft SQL Server.
Example: Optimizing the PARTITION_REF Function
The following request using the Adapter for Oracle calls the PARITION_REF function, which displays values from prior rows.
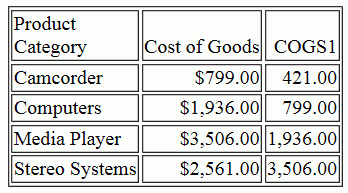
TABLE FILE WF_RETAIL_LITE SUM COGS_US COMPUTE COGS1 MISSING ON = PARTITION_REF(COGS_US,TABLE, -1); BY PRODUCT_CATEGORY WHERE TOTAL COGS_US GT 421; ON TABLE SET PAGE NOPAGE END
The following SQL is generated that calls the Oracle LAG function.
SELECT
"SK001_PRODUCT_CATEGORY",
"VB001_SUM_COGS_US",
"LAG002"
FROM (
SELECT
T7."PRODUCT_CATEGORY" AS "SK001_PRODUCT_CATEGORY",
SUM(T1."COGS_US") AS "VB001_SUM_COGS_US", LAG( SUM(T1."COGS_US"), 1) OVER( ORDER BY
T7."PRODUCT_CATEGORY") AS "LAG002"
FROM
( D99964R6_sales T1
LEFT OUTER JOIN
D99964R6_product T7
ON T7."ID_PRODUCT" = T1."ID_PRODUCT" )
GROUP BY
T7."PRODUCT_CATEGORY"
) X
WHERE ("VB001_SUM_COGS_US" > 421); The output is shown in the following image.
New Optimization Controls Using SET FEATOPT
|
How to: |
The adapter SET FEATOPT command can be used to selectively disable optimization of specific FOCUS features when the results may be undesirable. The ability to disable IF-THEN-ELSE and IF TOTAL or WHERE TOTAL optimization has been added. By default, all optimization features are enabled.
FEATOPT settings are displayed in Web Console debug mode.
The SET OPTIFTHENELSE command has been deprecated.
Syntax: How to Control IF TOTAL and WHERE TOTAL Optimization
ENGINE sqlengine SET FEATOPT TOTALTEST {ON|OFF}where:
- sqlengine
-
Specifies the adapter.
- ON
-
Passes the HAVING clause to the DBMS, as well as CASE logic, when applicable. The HAVING clause results from passing an IF TOTAL or WHERE TOTAL phrase from the FOCUS request. ON is the default value.
- OFF
-
Suppresses adding the HAVING clause to the generated SELECT.
Example: Disabling WHERE TOTAL Optimization Using FEATOPT
The following request against SQL Server has a WHERE TOTAL test.
SET TRACEUSER=ON SET TRACEON = STMTRACE//CLIENT SET TRACESTAMP=OFF TABLE FILE WF_RETAIL_LITE SUM COGS_US GROSS_PROFIT_US BY PRODUCT_CATEGORY WHERE TOTAL COGS_US GT 400000 END
The default generated SQL follows. The WHERE TOTAL test has been passed to the DBMS as a HAVING clause.
SELECT
T7."PRODUCT_CATEGORY",
SUM(T1."COGS_US"),
SUM(T1."GROSS_PROFIT_US")
FROM
( wrd_wf_retail_sales T1
LEFT OUTER JOIN
wrd_wf_retail_product T7
ON T7."ID_PRODUCT" = T1."ID_PRODUCT" )
GROUP BY
T7."PRODUCT_CATEGORY" HAVING
( SUM(T1."COGS_US") > 400000)
ORDER BY
T7."PRODUCT_CATEGORY";Adding the ENGINE SQLMSS SET FEATOPT TOTALTEST OFF command generates the following SQL. The WHERE TOTAL test has not been passed in the generated SQL and will be handled by FOCUS.
SELECT T7."PRODUCT_CATEGORY", SUM(T1."COGS_US"), SUM(T1."GROSS_PROFIT_US") FROM ( wrd_wf_retail_sales T1 LEFT OUTER JOIN wrd_wf_retail_product T7 ON T7."ID_PRODUCT" = T1."ID_PRODUCT" ) GROUP BY T7."PRODUCT_CATEGORY" ORDER BY T7."PRODUCT_CATEGORY";
Syntax: How to Control IF-THEN-ELSE Optimization
ENGINE sqlengine SET FEATOPT IFTHENELSE {ON|OFF}where:
- sqlengine
-
Specifies the adapter.
- ON
-
Passes the IF-THEN-ELSE expressions used to create a DEFINE field to the DBMS as CASE logic, when possible. ON is the default value. This optimization is subject to the limitations on optimizing DEFINE fields. The DEFINE field must be an object of a selection test or an aggregation request.
- OFF
-
Suppresses passing IF-THEN-ELSE expressions in the generated SQL.
Note: The SET OPTIFTHENELSE command has been deprecated.
Example: Disabling IF-THEN-ELSE Optimization Using FEATOPT
The following request against SQL Server has a DEFINE field created using IF-THEN-ELSE syntax.
SET TRACEUSER=ON SET TRACEON = STMTRACE//CLIENT SET TRACESTAMP=OFF DEFINE FILE WF_RETAIL_LITE DEF1 = IF (PRODUCT_CATEGORY EQ ' Accessories') AND (BRAND EQ 'Sony ') AND (PRODUCT_SUBCATEG EQ 'Headphones') THEN 1 ELSE 0; END TABLE FILE WF_RETAIL_LITE PRINT PRODUCT_CATEGORY PRODUCT_SUBCATEG BRAND WHERE DEF1 EQ 1 END
The default generated SQL follows. The IF-THEN-ELSE syntax has been passed to the DBMS as CASE logic.
SELECT
T7."BRAND",
T7."PRODUCT_CATEGORY",
T7."PRODUCT_SUBCATEG"
FROM
wrd_wf_retail_product T7
WHERE
((CASE WHEN ((T7."PRODUCT_CATEGORY" = ' Accessories') AND
(T7."BRAND" = 'Sony ') AND (T7."PRODUCT_SUBCATEG" =
'Headphones')) THEN 1 ELSE 0 END) = 1); Adding the ENGINE SQLMSS SET FEATOPT IFTHENELSE OFF command generates the following SQL. The IF-THEN-ELSE syntax has not been passed in the generated SQL and will be handled by FOCUS.
SELECT T7."BRAND", T7."PRODUCT_CATEGORY", T7."PRODUCT_SUBCATEG" FROM wrd_wf_retail_product T7;
New SQL Functions
|
Topics: |
The SQL Functions MOD, CEIL, FLOOR, LEAST, and GREATEST are now supported.
MOD: Returning the Remainder of a Division
|
How to: |
The SQL function MOD returns the remainder of the first argument divided by the second argument.
Syntax: How to Return the Remainder of a Division
MOD(n,m)
where:
- n
-
Numeric
Is the dividend (number to be divided).
- m
-
Numeric
Is the divisor (number to divide by). If the divisor is zero (0), MOD returns NULL.
Example: Returning the Remainder of a Division
MOD returns the remainder of n divided by m.
MOD(N,M)
For N=16 and M=5, the result is 1.
For N=34.5 and M=3, the result is 1.5.
CEIL: Returning the Smallest Integer Greater Than or Equal to a Value
|
How to: |
CEIL returns the smallest integer value not less than the argument. CEILING is a synonym for CEIL.
Syntax: How to Return the Smallest Integer Greater Than or Equal to a Value
CEIL(n)
where:
- n
-
Numeric or Alphanumeric
Is the value less than or equal to the returned integer. For exact-value numeric arguments, the return value has an exact-value numeric type. For alphanumeric or floating-point arguments, the return value has a floating-point type.
Example: Returning an Integer Greater Than or Equal to a Value
CEIL returns an integer greater than or equal to the argument.
CEIL(N)
For N=1.23, the result is 2.
For N=-1.23, the result is -1.
FLOOR: Returning the Largest Integer Less Than or Equal to a Value
|
How to: |
FLOOR returns the largest integer value not greater than a value.
Syntax: How to Return the Largest Integer Less Than or Equal to a Value
FLOOR(n)
where:
- n
-
Numeric or Alphanumeric
Is the value greater than or equal to the returned integer. For exact-value numeric arguments, the return value has an exact-value numeric type. For alphanumeric or floating-point arguments, the return value has a floating-point type.
Example: Returning an Integer Less Than or Equal to a Value
FLOOR returns an integer less than or equal to the argument.
FLOOR(N)
For N=1.23, the result is 1.
For N=-1.23, the result is -2.
LEAST: Returning the Smallest Value
|
How to: |
With two or more arguments, LEAST returns the smallest (minimum-valued) argument. The arguments are compared using the following rules:
- If any argument is NULL, the result is NULL. No comparison is needed.
- If the return value is used in an INTEGER context, or all arguments are integer-valued, they are compared as integers.
- If the return value is used in a floating-point context, or all arguments are floating-point-valued, they are compared as floating-point values.
- If the arguments comprise a mix of numbers and strings, they are compared as numbers.
- If any argument is a character string, the arguments are compared as character strings. In all other cases, the arguments are compared as binary strings.
Syntax: How to Return the Smallest Value
LEAST(value1, value2, ... , valuen)
where:
- value1, value2, ... , valuen
-
Numeric or alphanumeric
Are the values to be compared.
Example: Returning the Smallest Value
LEAST returns the smallest argument.
LEAST(X,Y,Z)
For X=2, Y=0, and Z=-1, the result is -1.
For X='B', Y='A', and Z='C', the result is 'A'.
GREATEST: Returning the Largest Value
|
How to: |
With two or more arguments, GREATEST returns the largest (maximum-valued) argument. The arguments are compared using the following rules:
- If any argument is NULL, the result is NULL. No comparison is needed.
- If the return value is used in an INTEGER context, or all arguments are integer-valued, they are compared as integers.
- If the return value is used in a floating-point context, or all arguments are floating-point-valued, they are compared as floating-point values.
- If the arguments comprise a mix of numbers and strings, they are compared as numbers.
- If any argument is a character string, the arguments are compared as character strings. In all other cases, the arguments are compared as binary strings.
Syntax: How to Return the Largest Value
GREATEST(value1, value2, ... , valuen)
where:
- value1, value2, ... , valuen
-
Numeric or alphanumeric
Are the values to be compared.
Example: Returning the Largest Value
GREATEST returns the smallest argument.
GREATEST(X,Y,Z)
For X=2, Y=0, and Z=-1, the result is 2.
For X='B', Y='A', and Z='C', the result is 'C'.
SQL Adapters Create Unique Keys for HOLD FORMAT SQL_SCRIPT
KEY information for SQL_SCRIPT files created using HOLD FORMAT SQL_SCRIPT is propagated to the Access File, which improves JOIN optimization.
Example: Propagating Key Information to the Access File Generated by HOLD FORMAT SQL_SCRIPT
The following request generates an SQL_SCRIPT file with two keys.
TABLE FILE WF_RETAIL_LITE SUM MIN.COGS_US MAX.GROSS_PROFIT_US BY BUSINESS_SUB_REGION BY STATE_PROV_CODE_ISO_3166_2 WHERE BUSINESS_SUB_REGION EQ 'Midwest' OR 'East' WHERE COUNTRY_NAME EQ 'United States' ON TABLE HOLD AS RETAILS FORMAT SQL_SCRIPT END
This request produces the following script file, retails.sql.
SELECT
T3."BUSINESS_SUB_REGION" AS "SK001_BUSINESS_SUB_REGION",
T3."STATE_PROV_CODE_ISO_3166_2" AS "SK002_STATE_PROV_CODE_ISO_3166",
MIN(T1."COGS_US") AS "VB001_MIN_COGS_US",
MAX(T1."GROSS_PROFIT_US") AS "VB002_MAX_GROSS_PROFIT_US
" FROM
wrd_wf_retail_sales T1,
wrd_wf_retail_customer T2,
wrd_wf_retail_geography T3
WHERE
(T2."ID_CUSTOMER" = T1."ID_CUSTOMER") AND
(T3."ID_GEOGRAPHY" = T2."ID_GEOGRAPHY") AND
(T3."COUNTRY_NAME" = 'United States') AND
(T3."BUSINESS_SUB_REGION" IN('Midwest', 'East'))
GROUP BY
T3."BUSINESS_SUB_REGION",
T3."STATE_PROV_CODE_ISO_3166_2"The RETAILS Master File follows.
FILENAME=RETAILS, SUFFIX=SQLMSS , $
SEGMENT=RETAILS, SEGTYPE=S0, $
FIELDNAME=BUSINESS_SUB_REGION, ALIAS=SK001_BUSINESS_SUB_REGION, USAGE=A25V, ACTUAL=A25V,
MISSING=ON,
TITLE='Customer,Business,Sub Region', $
FIELDNAME=STATE_PROV_CODE_ISO_3166_2, ALIAS=SK002_STATE_PROV_CODE_ISO_3166, USAGE=A5V, ACTUAL=A5V,
MISSING=ON,
TITLE='Customer,State,Province,ISO-3166-2,Code', $
FIELDNAME=COGS_US, ALIAS=VB001_MIN_COGS_US, USAGE=D20.2M, ACTUAL=D8,
MISSING=ON,
TITLE='Cost of Goods', $
FIELDNAME=GROSS_PROFIT_US, ALIAS=VB002_MAX_GROSS_PROFIT_US, USAGE=D20.2M, ACTUAL=D8,
MISSING=ON,
TITLE='Gross Profit', $The RETAILS Access File contains the key information.
SEGNAME=RETAILS, CONNECTION=wfretail, DATASET=RETAILS.SQL, KEY=BUSINESS_SUB_REGION/STATE_PROV_CODE_ISO_3166_2, SUBQUERY=Y, $
Enhancement to SQL Adapter Native Messaging Interface
In prior releases, the messages returned by an SQL adapter were displayed as one long string, making them difficult to read and understand. Starting in this release, native SQL messages will be presented in readable blocks, each as a FOC1500 message on a separate line. For example:
(FOC1400) SQLCODE IS -1 (HEX: FFFFFFFF) XOPEN: 42000 (FOC1500) : Microsoft SQL Server Native Client 10.0: [42000] Syntax error, (FOC1500) : permission violation, or other nonspecific error (FOC1406) SQL OPEN CURSOR ERROR. : __WF_RETAIL_WF_RETAIL_SALES
Improved Messaging for Environmental Problems
Messages that the SQL Adapters return to edaprint in case of a non-existent or incorrect path have been improved.
- Each environmental path is now clearly printed in edaprint.
- Those that do not exist are marked as follows.
----NOT FOUND
Random Data Sampling in SQL
Certain SQL Adapters such as Microsoft SQL Server, Oracle (ODBC and JDBC), and SAP HANA support random data sampling. For SAP HANA, sampling is only supported for column-based tables. A report can return a random sample of data from these RDBMSs using the following settings.
ENGINE engine SET TABLESAMPLING_TYPE {OFF|ROW|BLOCK}
ENGINE INT SET TABLESAMPLING_PERCENTAGE nwhere:
- engine
-
Specifies the adapter.
- OFF
-
Turns off table sampling.
- ROW
-
Uses row-based random sampling. This is the default value.
- BLOCK
-
Uses page-based random sampling.
- n
-
Is a number between 1 and 99 that specifies the percentage of records to be returned. The value blank, which is the default, indicates that sampling is not in effect.
For example, the following settings for SAP HANA return about 5% of the requested answer set.
ENGINE INT SET TABLESAMPLING_PERCENTAGE 5 ENGINE SQLHANA SET TABLESAMPLING_TYPE ROW
Consider the following request.
TABLE FILE filenameWRITE D END
The following SQL is generated as a result of these settings.
SELECT T1."D", SUM(T1."D") FROMtablename T1 TABLESAMPLE BERNOULLI(05) GROUP BY T1."D" ORDER BY T1."D";
Using BLOCK instead of ROW will generate native TABLESAMPLE SYSTEM(n) instead of BERNOULLI(n).
Optimization of Expressions on Partial Dates
Partial date formats such as YY, Q, D, and M, which are actually integer values, can now be optimized when used in expressions.
Adapter for Apache Drill
Apache Drill is a query engine for data managed by Hadoop in HDFS or Mapr-FS, a variety of NoSQL databases including HBase and MapR-DB, and MongoDB, and other data sources. Drill can use Hive metadata or derive metadata from self-describing data files.
Adapter for Db2
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for Db2.
Change to Multi-Row Inserts on z/OS
Db2 on z/OS changed the default behavior for multiple-row inserts from non-atomic to atomic. This feature resets the default behavior of the Adapter for Db2 back to non-atomic. Non-atomic maximizes the number of valid rows that are added to a table when a non-fatal error (such as duplicate insert) occurs.
Support for TIMESTAMP for CDC_START on z/OS
Db2 version 10 now supports the Timestamp value of a START parameter in a CDC synonym.
Conversion to ANSI Date, Time, and Timestamp Literals
When the Adapter for Db2 converts a request that contains a date, time, or timestamp literal to SQL, it converts the literal to ANSI standard format in the generated SQL.
For example, consider the following WHERE phrase:
WHERE DATECONST1 EQ '19010228'
The adapter will convert the WHERE phrase to the following predicate in the generated SQL:
WHERE (T1."DATECONST1" = DATE '1901-02-28')
Support DECFLOAT Data Type as MATH and XMATH
The new Db2 data types MATH and XMATH support the necessary precision for compatible decimal computation. The Db2 data type DECFLOAT(16) can be mapped as ACTUAL format MATH or FLOAT, and the Db2 DECFLOAT(34) data type can be mapped as ACTUAL format XMATH or FLOAT using the following settings.
SQL DB2 SET CONV_DECFLOAT16 MATH SQL DB2 SET CONV_DECFLOAT16 FLOAT SQL DB2 SET CONV_DECFLOAT34 XMATH SQL DB2 SET CONV_DECFLOAT34 FLOAT
The default precision is 18 and the default scale is 2 for the MATH data type. You can change these defaults using the following commands, where p is the precision and s is the scale.
SQL DB2 SET CONV_DECFM_PREC p SQL DB2 SET CONV_DECFM_SCALE s
The default precision is 34 and the default scale is 2 for the XMATH data type. You can change these defaults using the following commands, where p is the precision and s is the scale.
SQL DB2 SET CONV_DECFX_PREC p SQL DB2 SET CONV_DECFX_SCALE s
Adapter for C9 INC
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for C9 INC.
New Setting Available for Temporal Lower Boundary Date
The TREND_LOW_BOUNDARY = YYYY-MM-DD setting provides a lower boundary for the temporal trending period that will be used when the lower boundary is not specified by a TABLE query FROM-TO clause.
The default c9 value is 1970-01-01. Historical data filtered by the following expression may be excessive and cause performance problems.
WHERE DAILY/MONTHLY/QUARTERLY/YEARLY_TREND FROM '1970-01-01' TO CURRENT_DATE
This setting will relieve such problems.
Adapter for Cloudera Impala
The Adapter for Cloudera Impala provides for analysis of both structured and complex data. Impala provides a JDBC driver and the Hive Query Language, a SQL-like interface with a real time query capability that shares the metadata layer and query language with Hive.
Adapter for EXASol ODBC
|
Topics: |
The Adapter for EXASol ODBC is new in this release and can be found under SQL Adapters on the Web Console. The adapter provides read/write access to data stored in an EXASOL in-memory database is available on Windows and RH Linux. The adapter uses the EXASolution ODBC driver API.
Adapter for EXASol ODBC: Extended Bulk Load
An extended bulk load option is available that uses the IMPORT command for faster loading.
Adapter for Google BigQuery
The Adapter for Google BigQuery is new in this release and can be found under SQL Adapters on the Web Console. The adapter is used to load data into the Google BigQuery environment and report against the information that is residing in the Google BigQuery environment. BigQuery provides a REST-based API that requires all requests to be authorized by an authenticated user or a service account.
Adapter for Hive
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for Hive.
Synonym Creation for SQL Strings
The adapter supports Create Synonym for an External SQL Script.
Insert/Update for ORC Files
As of Hive 0.14, the UPDATE operation is supported for data stored as Optimized Row Columnar (ORC) format. While not designed for OLTP, this does provide an option for dimension tables and for correcting data.
DataMigrator and MODIFY as well as SQL Pass through can take advantage of this capability.
When the Hive metadata is created it must contain these additional parameters:
CLUSTERED BY (column [,column..]) INTO n BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true')Where the number of buckets and one more column names that are used to cluster the data are specified.
Note that DataMigrator currently requires a key column to be identified to perform update operations. While Hive does not identify columns as keys, since bucketed columns cannot be updated, they should be so identified. Before creating a data flow to perform updates, edit the synonym for the target table and select the Key Component checkbox for the bucketed columns and any others required to uniquely identify the row.
Adapter for i Access
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for i Access.
JDBC Adapter Configuration Available
A new SQLIIA JDBC-based adapter is available to enable access to the IBM i platform from UNIX, Windows, and Linux.
Adapter for Informix
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for Informix.
Adapter for Informix Supports Extended Bulk Load
DataMigrator with a target table in Informix supports Extended Bulk Load using the native DBLOAD utility.
Adapter for Jethro
Jethro is an acceleration engine that makes real-time Business Intelligence work on Big Data. The adapter is available for ODBC (on Windows only) and JDBC (on Linux/Unix/Windows).
Adapter for MariaDB
|
Topics: |
The Adapter for MariaDB is new in this release and can be found under SQL Adapter on the Web Console. The adapter provides read/write access to data stored in the open source MariaDB database using the MariaDB Connector/J.
Adapter for MariaDB: Change Data Capture (CDC) Support
DataMigrator supports Change Data Capture (CDC) for MariaDB with Load Type IUD.
Adapter for Microsoft SQL Server
The following features are supported for Microsoft SQL Server in this release.
Adapter for Microsoft SQL Server: Support for Computed Columns as R/Only
Adapters for MS SQL (SQLMSS and MSODBC) now map SQL Server computed columns as read-only, with the FIELDTYPE=R attribute.
JDBC and ODBC Adapters for Microsoft SQL Server Support Version 2016
ODBC and JDBC Adapters for Microsoft SQL Server support the recently released Microsoft SQL Server version 2016, ODBC driver version 13, and JDBC driver version 6.
ODBC Adapter for Microsoft SQL Server Supported on Red Hat Linux
ODBC based access to MS SQL Server is provided from Linux Red Hat 6 on the Intel x64 platform. Performance savings for large answer set retrieval can reach 50% compared to JDBC access from Linux.
ODBC Adapter for Microsoft SQL Server Support for Extended Bulk Load
The Adapter for MSODBC Supports extended bulk loading via MS Bulk Copy utility on Windows and Linux.
ODBC Adapter for Microsoft SQL Server Supports Change Data Capture for NVARCHAR(MAX) Fields
When a column has the data type NVARCHAR(MAX), the Synonym Editor now creates the synonym with USAGE and ACTUAL formats A32765V when the Synonym Candidates are restricted to Table Log Records.
Note: The server must be configured for Unicode to properly report from National Fields.
If the length of the data is longer than 32765, the following message is generated:
(FOC1362) COLUMN name IS TRUNCATED IF DATA LENGTH EXCEEDS 32765
Adapter for MySQL
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for MySQL.
Change Data Capture (CDC) Support
The Adapter for MySQL now supports Change Data Capture (CDC).
Adapter for Netezza
|
Topics: |
This section provides descriptions of new features for the Adapter for Netezza.
Adapter for Netezza: Support for Bulk Load
The Adapter for Netezza supports extended bulk loading using the nzload utility.
Adapter for ODBC
|
Topics: |
This section provides descriptions of new features for the generic ODBC Adapter.
Adapter for ODBC: Support for Wide API
The Generic ODBC Adapter has been upgraded to utilize the wide ODBC API.
Adapter for Oracle
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for Oracle.
Support for Power Linux LE With Instant Client
The Adapter for Oracle is now supported on IBM Power Linux Little Endian systems using the Oracle Instant Client Basic package.
New Setting to Map FLOAT Data Type as DECIMAL
The following new Adapter for Oracle setting maps the Oracle FLOAT and FLOAT(126) data types to Float or to Decimal.
ENGINE SQLORA SET ORAFLOAT [FLOAT|DECIMAL[p s] ]
where:
- FLOAT
-
Maps the Oracle FLOAT and FLOAT(126) data types to USAGE=D20.2, ACTUAL=D8. This is the default value
- DECIMAL[p s]
-
Maps the Oracle FLOAT and FLOAT(126) data types to Decimal with precision = p and scale = s. If precision and scale values are omitted, the precision defaults to 33 and the scale to 2.
This setting is expected to be used on case-by-case basis after consulting with Information Builders Technical Support Services. It compensates for the Oracle proprietary implementation of FLOAT and FLOAT(126) data types that deviate from the IEEE 754 standard.
Note that Oracle BINARY_FLOAT and BINARY_DOUBLE data types are not affected by the setting since these types conform to the IEEE 754 standard.
Connection to Database Running on Amazon RDS
The Adapter for Oracle can access Amazon RDS running an Oracle DB instance. This is implemented by using a long connection string, such as the following, instead of a TNS alias.
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dns_of_db_instance) (PORT=listener_port))(CONNECT_DATA=(SID=database_name)))
where:
- dns_of_db_instance
-
Is the DNS of the database instance.
- listener_port
-
Is the Oracle TCP listener port number.
- database_name
-
Is the database name.
Support for Extended Bulk Load
The Adapter for Oracle Supports Extended Bulk Load based on the Direct Path Load API.
Adapter for Oracle Reads XMLType Data Type Using DB_EXPR
The Oracle XMLType data type can be mapped with USAGE=TX50L, ACTUAL=TX. The Access File then specifies attributes needed for retrieving the data using the DB_EXPR function.
The following Master File declares a field named xmltypefield whose data type is XMLType:
FILENAME=ORAXML_SRZ, SUFFIX=SQLORA , $ SEGMENT=ORAXML_SRZ, SEGTYPE=S0, $ FIELDNAME=I, ALIAS=I, USAGE=I11, ACTUAL=I4, MISSING=ON, $ FIELDNAME=xmltypefield, ALIAS=X, USAGE=TX50L, ACTUAL=TX, MISSING=ON, $
The following Access File specifies the attributes for reading the XMLType field:
SEGNAME = segname, TABLENAME = tablename,$ FIELD=xmltypefield, SQL_FLD_OBJ_TYPE=OPAQUE, SQL_FLD_OBJ_PROP=, SQL_FLD_OBJ_EXPR='DB_EXPR(XMLSERIALIZE(DOCUMENT "xmltypefield"))',$
where:
- SQL_FLD_OBJ_TYPE=OPAQUE
-
Indicates that the field can be processed only through DB_EXPR.
- SQL_FLD_OBJ_EXPR='DB_EXPR(XMLSERIALIZE(DOCUMENT "xmltypefield"))'
-
Is the Oracle SQL Expression that reads the XML document stored in the field.
Example: Using an Oracle XMLType Field in a Request
The following request retrieves the XML document stored in column XMLTYPEFIELD for id=112.
TABLE FILE ORAXML_SRZ PRINT XMLTYPEFIELD WHERE I EQ 112 END
The following SQL is generated and passed to Oracle.
SELECT T1."I", (XMLSERIALIZE(DOCUMENT T1."XMLTYPEFIELD")) FROM PODOC T1 WHERE (T1."I" = 112);
Adapter for Oracle: Support for Long IN-list
The Adapter for Oracle now splits a long IN-list generated, for example, when BY HIERARCHY is used in reports. This enables it to overcome the Oracle limit of 1000 elements and pass optimized SQL to the DBMS.
Adapter for Apache Phoenix for HBase
Apache Phoenix provides SQL read/write access to Apache HBase (and MapR-DB) a NoSQL database distributed with Hadoop.
For full functionality this adapter requires Phoenix release 4.5.0 or later.
Adapter for SAP HANA
|
Topics: |
The following features have been added for the Adapter for SAP HANA.
Optimization of Simplified Functions POSITION and TOKEN
Simplified functions POSITION and TOKEN are optimized by the Adapter for SAP HANA.
Support for NCLOB/TEXT Data Types
The Adapter for SAP HANA supports the TEXT data type in HANA column mode as format NCLOB.
Adapter for Sybase
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for Sybase.
Adapter for Sybase IQ Support for Unicode Extended Bulk Load
The Adapter for Sybase IQ supports Unicode Extended Bulk Load.
Adapter for Teradata
|
Topics: |
This section provides detailed descriptions of new features for the Adapter for Teradata.
Support for Wide ODBC API
A new interface for Teradata is introduced that is based on the wide ODBC API. This interface supports Unicode and offers better performance on some platforms (for example, Windows and Linux x64/x86) compared to the Teradata ODBC interface that is not utilizing the wide API. This wide ODBC API interface is supported with TTU v.15.0 or higher.
READONLY Fields in Extended Bulk Load
Loading into Teradata using Extended Bulk Load is now supported even when the server metadata contains READONLY fields. Such fields will be skipped and remained unchanged during loading.
Distinguishing Between Macros and Stored Procedures
The following Access File attribute has been introduced to identify whether the synonym represents a Teradata Macro or Stored Procedure.
STPTYPE = {MACRO|SP}Support for Version 15.10
The Teradata CLI and ODBC adapters support Read/Write access to Teradata Version 15.10.
| WebFOCUS | |
|
Feedback |