Merging Data: MATCH
|
Topics: |
|
How to: |
You can merge two or more data sources, and specify which records to merge and which to eliminate, using the MATCH command. The command creates a new data source (a HOLD file), into which it merges fields from the selected records. You can report from the new data source and use it as you would use any other HOLD file. HOLD files are discussed in Advanced Features
You can select the records to be merged into the new data source by specifying sort fields in the MATCH command. Specify one set of sort fields, using the BY phrase, for the first data source, and a second set of sort fields for the second data source. The MATCH command compares all sort fields that have been specified in common for both data sources, and then merges all records from the first data source whose sort values match those in the second data source into the new HOLD file. You can specify up to 128 sort sets. This includes the number of common sort fields.
In addition to merging data source records that share values, you can merge records based on other relationships. For example, you can merge all records in each data source whose sort values are not matched in the other data source. Yet another type of merge combines all records from the first data source with any matching records from the second data source.
You can merge up to 16 sets of data in one Match request.
The syntax of the MATCH command is similar to that of the TABLE command:
MATCH FILE file1 . . . RUN FILE file2 . . . [AFTER MATCH merge_phrase] RUN FILE file3 . . . [AFTER MATCH merge_phrase] END
The merge phrase specifies how the retrieved records from the files are to be compared.
Note that a RUN command must follow each AFTER MATCH command, except for the last one. The END command must follow the final AFTER MATCH command.
MATCH generates a HOLD file. You can print the contents of the HOLD file using the PRINT command with the wildcard character (*).
Syntax: How to Specify Merge Phrases
The results of each merge phrase are graphically represented using Venn diagrams. In the diagrams, the left circle represents the old data source, the right circle represents the new data source, and the shaded areas represent the data that is written to the HOLD file.
|
AFTER MATCH Command |
Description |
|---|---|
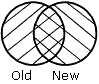 |
OLD-OR-NEW specifies that all records from both the old data source and the new data source appear in the HOLD file. This is the default, if the AFTER MATCH line is omitted. |
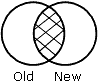 |
OLD-AND-NEW specifies that records that appear in both the old and new data sources appear in the HOLD file. This is the intersection of the sets. |
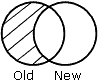 |
OLD-NOT-NEW specifies that records that appear only in the old data source appear in the HOLD file. |
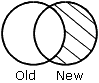 |
NEW-NOT-OLD specifies that records that appear only in the new data source appear in the HOLD file. |
 |
OLD-NOR-NEW specifies that only records that are in the old data source but not in the new data source, or in the new data source but not in the old, appear in the HOLD file. This is the complete set of non-matching records from both data sources. |
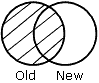 |
OLD specifies that all records from the old data source, and any matching records from the new data source, are merged into the HOLD file. |
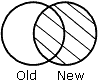 |
NEW specifies that all records from the new data source, and any matching records from the old data source, are merged into the HOLD file. |
In the following request, the high-order sort field is the same for both files.
MATCH FILE EDUCFILE SUM COURSE_CODE BY EMP_ID RUN FILE EMPLOYEE SUM FIRST_NAME BY EMP_ID BY LAST_NAME AFTER MATCH HOLD OLD-OR-NEW END -****************************** -* PRINT CONTENTS OF HOLD FILE -****************************** TABLE FILE HOLD PRINT * END
The merge phrase used in this example was OLD-OR-NEW. This means that records from both the first (old) data source plus the records from the second (new) data source appear in the HOLD file.
Run the request. The output is:
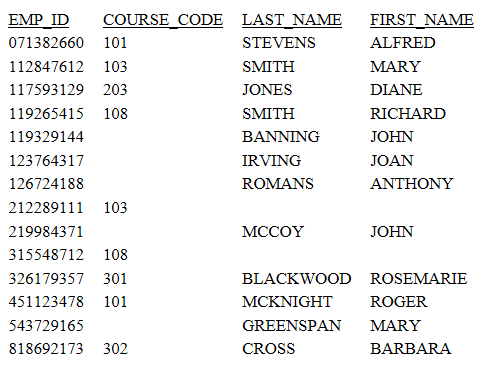
MATCH Processing With Common High-Order Sort Fields
When you construct your MATCH so that the first sort (BY) fields (called the common high-order sort fields) used for both data sources are the same in name and format, the match compares the values of the common high-order sort fields.
At least one pair of sort fields is required. Field formats must be the same. In some cases, you can redefine a field format using the DEFINE command. If the field names differ, use the AS phrase to rename the second sort field to match the first.
When you are merging files with common sort fields, the following assumptions are made:
- If one set of sort fields is a subset of the other, a one-to-many relationship is assumed.
- If neither set of sort fields is a subset of the other, a one-to-one relationship is assumed. At most, one matching record is retrieved.
Example: Merging With a Common High-Order Sort Field
This request combines data from the EMPLOYEE and EMPDATA data sources. The sort fields are EID and PIN.
MATCH FILE EMPLOYEE PRINT LN FN DPT BY EID RUN FILE EMPDATA PRINT LN FN DEPT BY PIN AS 'EID' AFTER MATCH HOLD OLD-OR-NEW END TABLE FILE HOLD PRINT * END
Example: Merging Without a Common High-Order Sort Field
If there are no common high-order sort fields, a match is performed on a record-by-record basis. The following request matches the data and produces the HOLD file:
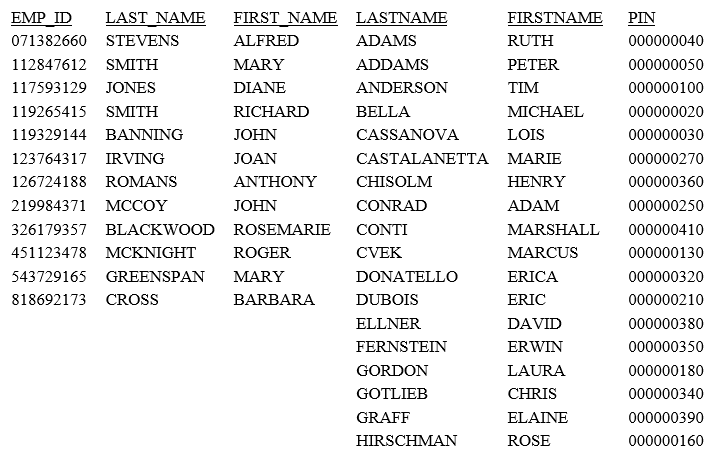
MATCH FILE EMPLOYEE PRINT LAST_NAME AND FIRST_NAME BY EMP_ID RUN FILE EMPDATA PRINT PIN BY LASTNAME BY FIRSTNAME AFTER MATCH HOLD OLD-OR-NEW END TABLE FILE HOLD PRINT * END
The retrieved records from the two data sources are written to the HOLD file. No values are compared.
Run the request. The output is:
| WebFOCUS | |
|
Feedback |