Loading Data into Apache Spark Using DataMigrator
DataMigrator can be used to load data from any accessible data source into Hadoop and create metadata in Hive. Currently, the only load type supported is Extended Bulk Load. The exception are files stored as ORC (Optimized Row Columnar) format, for which Insert/Update can be used.
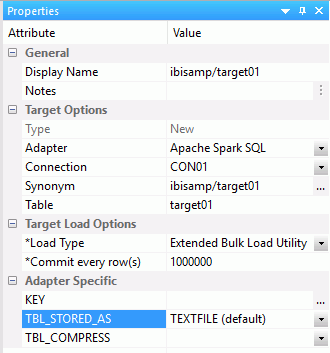
The table should be stored as TEXTFILE (default), ORC, or Parquet, as shown in the following image.
For more information, see the DataMigrator User's Guide.
| WebFOCUS | |
|
Feedback |