Data Transformation
The following options are available on the Transform tab in RStat. You may also access the Transform tab through the Tools menu.
Note: Options may vary depending on the type of data that is selected.
Data transformation allows users to derive new variables from existing ones. The transformation process can change the scale of the variables, the grouping of the values, and the type of the variable. The Transform tab also allows you to impute missing values, for example, replace the missing values with new values. As with transformations, a new variable with the imputed values will be created. Transformations and imputation make the data more useful in the modeling process.
When transformations are performed:
- A new variable name is automatically generated for each transformed variable. The name is derived from the original variable name, and a prefix that indicates the type of transformation is applied to it. For example, if an income variable is transformed using Recenter, the new variable will be called RRC_Income.
- Only one
transformed variable per each transformation type is allowed. For example,
generating multiple transforms of the same type on the same variable
will not result in the creation of multiple transformed variables.
If you run the same transformation method on the same variable but with a new value, for example, if you are using imputations and you change the constant to a new method, the transformed variable will be replaced by the new transformed variable.
- Even if sampling is selected, transformations will be applied to the entire data set.
- The transformed variable is automatically added to the Data tab. Its role is inherited from the role of the original variable. The original variable role is automatically changed to Ignore. The assumption is that the transformed variable will be used for analysis and modeling.
- Types of Transformations Included With RStat
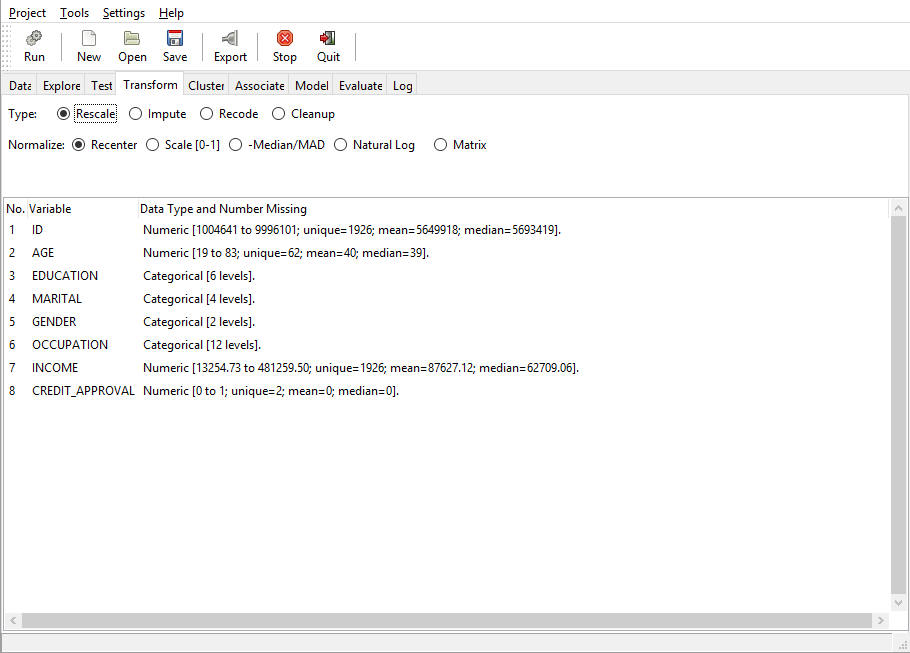
- Rescale
-
There are two types of rescaling transformations.
Normalize. The terms rescaling, normalization, and standardization are frequently used interchangeably. They denote the conversion of one unit of measurement into another by applying a mathematical formula. For example, the conversion from Celsius to Fahrenheit involves a process of multiplying by a constant and adding a constant. There are many reasons to perform normalization of the data. One reason is to make a skewed distribution normal. For example, income is frequently skewed. Using a log transformation will normalize it. Another reason is to make two measures more comparable in magnitude. For example, age and income differ significantly in magnitude, but using scale, they can be rescaled from 0 to 1 and thus used in cluster analysis.
- Recenter (RRC). Rescales the values in the data set so that the mean of the transformed variable is 0 and the standard deviation is 1. It is also referred to as standardization, that is, the process of subtracting a measure of location and dividing by a measure of scale. For example, subtracting the mean (location) and dividing by the standard deviation (scale) generates a variable with a mean of 0 and standard deviation of 1.
- Scale [0-1] (R01). Rescales the variable so that the new values range between 0 and 1. It is often referred to as Normalization, using the minimum and the range of the variable in order to make all the elements lie between 0 and 1.
- -Median/MAD (RMD). Rescales the values so that the median for the new data set is zero and the median absolute deviation is 1. This is a variant of the Recenter methods using the median instead of the mean and the absolute deviation instead of the standard deviation.
- Natural Log (RLG). Transforms the original value into the log values. A logarithm is the power (exponent) to which a base number must be raised in order to get the original number. Thus, log10(100)=2.
- Matrix (RMA). If one variable is selected, each value will be divided by the sum of the entire data set. If more than one variable is selected, transformed variables for each selected variable will be created. The values of the transformed variables will be formed by dividing each original value by the sum of all selected variables (the matrix).
The following image displays the Rescale transformations.
- Impute
-
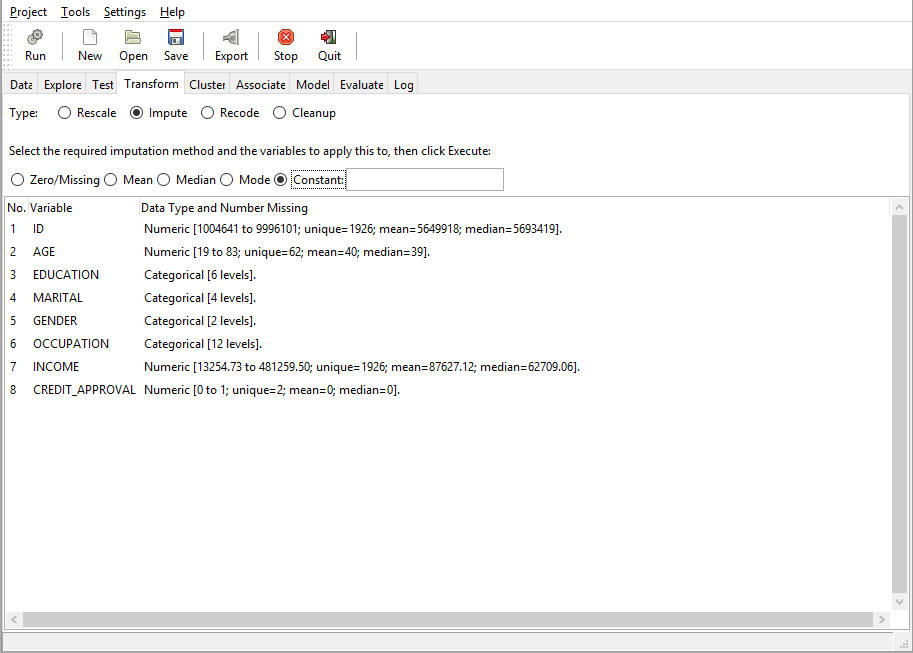
Imputation is used to fill in the missing values in the data. The Zero/Missing imputation is a very simple method. Any missing numeric data is simply assigned 0, and any missing categoric data is put into a new category, Missing. Mean, Median, and Mode replace missing values with the population mean, median, or mode.
- Zero/Missing (IZR). The Zero/Missing imputation is a very simple method. Any missing numeric data is simply assigned 0, and any missing categoric data is put into a new category called Missing.
- Mean (IMN). The missing values are replaced with the mean value. The mean method cannot be applied to categoric variables.
- Median (IMD). The missing values are replaced with the median value. The mean method cannot be applied to categoric variables.
- Mode (IMO). The missing values are replaced by the mode. For categoric values, the missing values will be replaced by the most frequently occurring category, excluding Missing.
- Constant (ICN). The missing values will be replaced by a user-provided constant. The method can be used on both numeric and categoric variables.
The following is an image of the Impute options in the Transform tab.
- Recode
-
Recoding is the process of reassigning values to new categories or reassigning a variable to a new type.
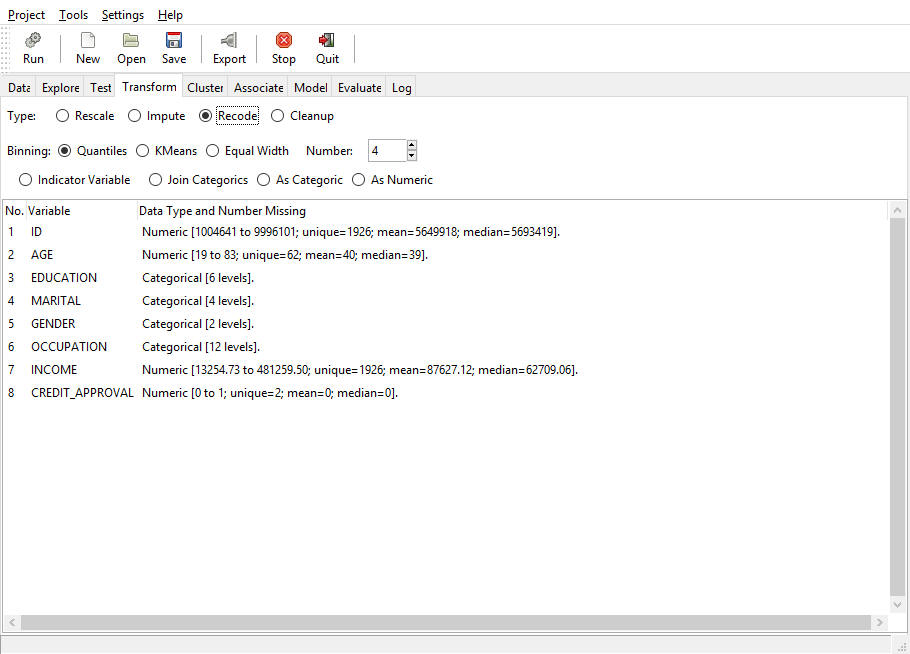
Binning. Binning is a process of grouping measured data into classes or categories. There are several types of binning transformations.
- Quantiles (BQx). Assigns the values to four groups of approximately equal size.
- KMeans (BKx). KMeans clustering will be used to assign the observations (rows of data) to clusters (groups). Only numeric variables can be clustered. If any categoric variables are selected, you will receive a message indicating that clustering is available only for numeric data.
- Equal Width (Bex). The
range between the minimum to maximum values will be split into a
user-defined number of groups. The groups will have equal width.
- Number. The spinner control allows users to define the number of groups.
- Indicator Variable (TIN). Assigns each value of a particular categoric variable to a new numeric variable. The categoric value (for example Male) is set to 1 in the new variable, while all the other categories (Female, unknown) are set to 0. The process is repeated for each value in the original categoric variable. The new indicator variables are also referred to as dummy variables, which can be used independent of one another in a regression analysis.
- Join Categorics (TNJ). Concatenates the values in two categoric variables. The transformation can be applied to only two categoric variables.
- As Categoric (TFC). Transforms a numeric variable into a categoric value, while turning numbers into strings. This allows you to treat numbers as factors in the modeling process. For example, if you have five groups, labeled 1 to 5, and if they are loaded as numeric variables, the regression model will estimate one coefficient. If you transform them to five factors, the regression will estimate one coefficient for each group.
- As Numeric (TFN). Converts
a categoric variable into a numeric variable by assigning a number
to each category. For example, you may have ordered categories,
such as Very Strong, Strong, Somewhat Strong, and so on. It may
be useful to convert to numeric to perform various tests on the
rankings.
The following is an image of the Recode option on the Transform tab.
- Cleanup
-
Cleanup allows users to delete various elements from the loaded data set. This is particularly useful in freeing up memory, especially if the modeler is creating many transformed variables for testing purposes.
- Delete Ignored. Deletes any variable whose Role is set to Ignore in the Data tab.
- Delete Selected. Deletes the selected variables in the Transform tab.
- Delete Missing. Deletes any variable that contains missing values.
- Delete Obs with Missing. Deletes any rows in the data that contain missing values in any of the variables.
The following is an image of the Cleanup options in the Transform tab.

| WebFOCUS | |
|
Feedback |