Magnify Search Protocols for Indexing Documents
|
Topics: |
When Magnify Search is fed data to be stored as search content, it expects an incoming document in a specific format. Using Format Magnify, the WebFOCUS protocol is transformed by the WebFOCUS Reporting Server into a document following these protocols. Using DataMigrator, the document is manually created and must adhere to these protocols. In iWay, the IEI Feed Agent converts the process flow output to adhere to those protocols. The incoming feed document can contain one or more records or search results.
iWay Service Manager (iSM) and the FORMAT MAGNIFY command can be used to extract, transform, and load data into the Magnify Search index library from various sources, such as databases, legacy systems, and transactional messages. Each document generated must be well-formed XML that adheres to the Magnify Search feed protocol. This section describes the required document format, whether you are using the IEI Feed Agent in iSM or the FORMAT MAGNIFY command to feed data to Magnify Search.
Note: The IEI Feed Agent and FORMAT MAGNIFY command generate the final document in adherence with the Magnify Search protocols. However, the developer must prepare the data in accordance with these protocols.
The following image illustrates a well-formed XML document that adheres to the Magnify Search protocol specification.
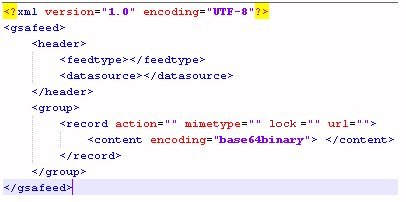
General Specification
|
Topics: |
Each incoming feed document that is indexed by Magnify Search requires a header and record element. These elements provide information, such as how the document should be fed to the index library and the type of document that is being indexed.
Header Element
The header section contains the following document-level Magnify Search feed properties:
- feedtype
-
Contains one of the following values:
- full replaces all previous data in the index from the data source. If a record is repeated in the feed, it is duplicated in the Magnify Search index library. Therefore, the full feedtype is recommended only when there are no duplicate records.
- incremental updates an existing record in the index or adds the data as a new record. The record is first matched using the WF_INDEX_UNIQUE_KEY meta tag. Otherwise, the URL value is used. This mode prevents duplicate records from being added to the index library.
Important: It is a best practice to always index data using WF_INDEX_UNIQUE_KEY.
- datasource
-
Is the source of the data to be fed to the search engine. If the library is not found, Magnify Search creates it dynamically. Magnify Search index libraries are created in the location specified by the magnify_root parameter configured in the WebFOCUS Administration Console. For more information, see the Magnify Search Security and Administration manual.
Record Element
The record element contains attributes that define record-level Magnify Search feed properties and the content being indexed. The information contained in the record element varies for each protocol. However, the record element defines the following for each protocol:
- attribute:action
-
The action attribute specifies how to apply each record found in the incoming document to a Magnify Search index and contains one of the following values:
- ADD inserts or updates a record. Adds are influenced based on the feedtype set and require UNIQUE_KEY for update.
- DELETE prevents a document from being searchable. The disk space is reserved until it is reused by the index library when space is needed or when an administrator optimizes the index.
- attribute:mimetype
-
The mime type attribute defines the type of content to process in the content section of the record. This value is specific to each protocol.
Note: This attribute can be defined per record when more than one record is sent in a single document.
- attribute:url
-
Specifies the default record ID in the Magnify Search index library. In addition, this URL is used by the Magnify Search interface as follows:
- Provides the information required to build the Dynamic Categorization Tree.
- Gets concatenated with the meta tags for accessing WebFOCUS reports.
Note: The URL must be encoded.
The document and record-level properties are defined in the IEI Feed Agent properties tab in iWay Integration Tools (iIT) Designer and in the FORMAT MAGNIFY ENGINE SET statements. The base URL is defined by the BASE URL property in both the IEI Feed Agent and FORMAT MAGNIFY statements. The query string parameters appended to the records URL attribute are generated by user-defined properties of the IEI Feed Agent or in the FORMAT MAGNIFY alias naming conventions.
- node:content
-
Defines the actual document being indexed with Magnify Search. The attribute encoding must be set to base64binary, and the content assigned within this node must be base64 encoded.
The content document is generated using the iWay process flow described in Supporting Information for iWay or the Indexing Using the FORMAT MAGNIFY Command.
Protocol Specification
|
Topics: |
|
Reference: |
- Record. Used for structured and semi-structured data.
- URL. Used for web-accessible files.
- Document. Used for embedded files.
Reference: Record Protocol
- TITLE. Is the text assigned as the Search Results main link text. This can be enriched with HTML.
- META TAG. Is the field name and its value stored in the index with the search result. For more information on the available meta tags, see Supporting Information for iWay.
- BODY. Content indexed and made available for searching.
Note: The BODY element is stored as IBI_CONTENT in the Magnify Search index library, which can be accessed using tools such as Lucene Luke.
The following image illustrates a decoded document that can be indexed using the record protocol.
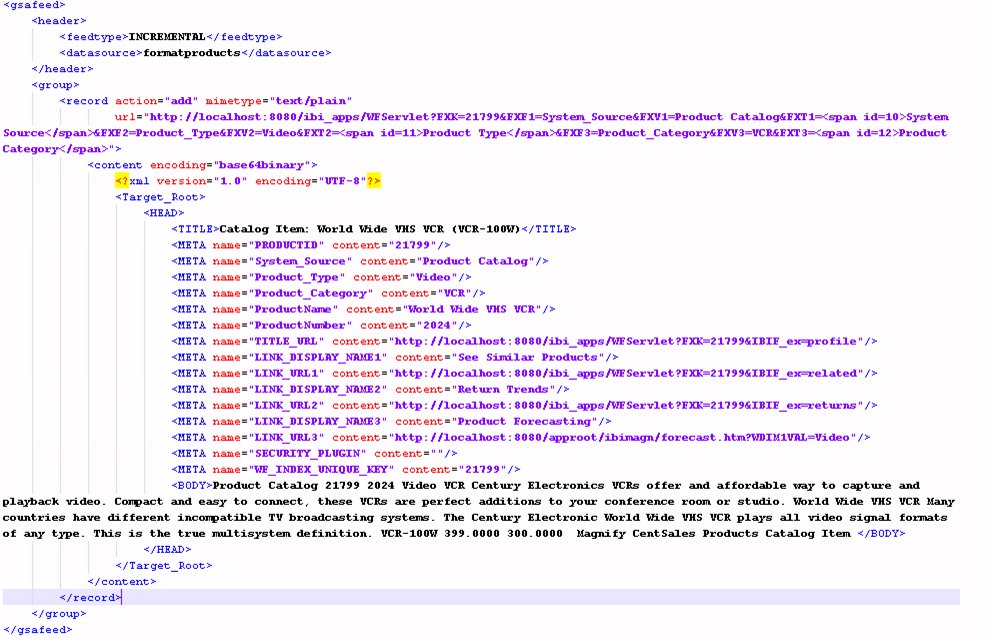
Note: Magnify Search requires base64 encoded content and an encoded record URL.
Reference: URL Protocol
The URL protocol is used for web-accessible files and is recommended for larger files. Magnify Search fetches the document, reads it, and indexes the content. The mime type attribute of the record must be set to application/openurl. Magnify Search locates the file based on the URL attribute value of the record. If a URL cannot be accessed or indexed, it is logged in the application server log files. The document inserted into the content section is also an XML document with an ENCODEDDOCUMENT root element containing HEAD, DOCUMENT, and AUTHENTICATION sections.
- TITLE. Is the text assigned as the Search Results main link text. This can be enriched with HTML.
- META TAG. Is the field name and its value stored in the index with the search result. For more information on the available meta tags, see Supporting Information for iWay.
The DOCUMENT section contains the following attributes:
- Password. Required if the file is password protected. The password is used to read the file for indexing and is optional.
- Mimetype. Must be set to file/auto. The document is passed to the Magnify Search parser to process various file types based on information found in the document header.
The content element is empty, since Magnify Search fetches the content based on the URL attribute value of the record.
The AUTHENTICATION section contains the wwwauthenticateuserid and wwwauthenticatepassword attributes, which are used to access the domain where the document is located.
The contents of the document indexed are stored as IBI_CONTENT in the Magnify Search index library, which can be accessed using tools such as Lucene Luke.
The following image illustrates a decoded document that can be indexed using the URL protocol.
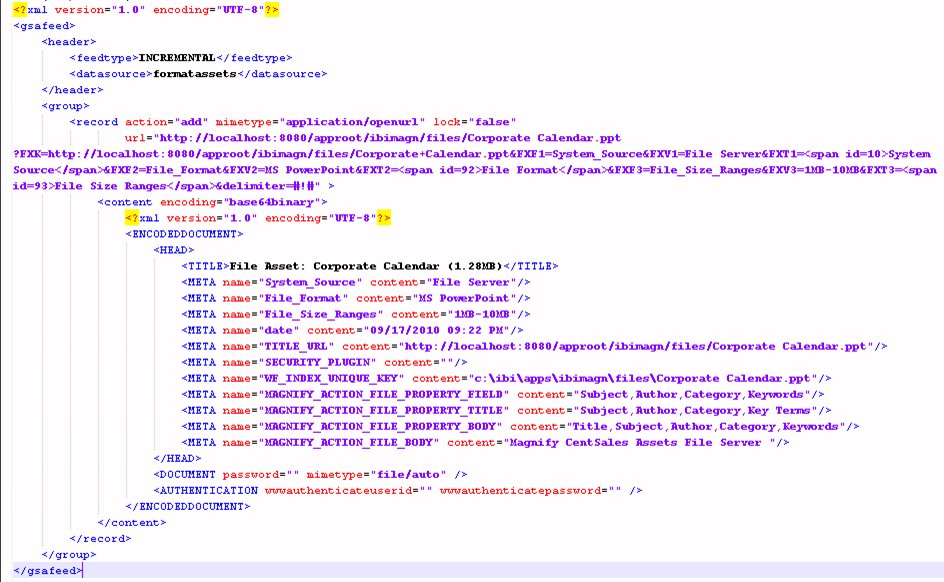
Note: Magnify Search requires base64 encoded content and an encoded record URL.
Reference: Document Protocol
The document protocol is used when files can be embedded into the document that is being indexed. Magnify Search reads in and indexes the content of the document. The mime type attribute of the record must be set to application/encodeddocument.
The document inserted into the content section is an XML document with an ENCODEDDOCUMENT root element containing a HEAD and DOCUMENT section.
The following elements are contained in the HEAD section:
- TITLE. Is the text assigned as the Search Results main link text. This can be enriched with HTML.
- META TAG. Is the field name and its value stored in the index with the search result. For more information on the available meta tags, see Supporting Information for iWay.
The DOCUMENT section contains attributes about the embedded file within the document tags. Encoding must be set to base64binary. The mime type must be set to file/auto. The fetched document is passed to the Magnify Search parser to process various file types based on information natively found in the document header. A password is required if the file is password protected. The password is used to read the file for indexing and is optional.
The contents of the document indexed are stored as IBI_CONTENT in the Magnify Search index library, which can be accessed using tools such as Lucene Luke.
The following image illustrates a decoded document that can be indexed using the document protocol.

Note: Magnify Search requires base64 encoded content and an encoded record URL.
Embedding files into the Magnify Search feed document can be done using the file object in iWay Service Manager (iSM). For more information on the iWay process flow, see Supporting Information for iWay. The embedded file must be base64 encoded.
XML Protocol of Search Result Output
|
Topics: |
- TM
- Q
- PARAM
- RES
- M
- NB
- NU
- R
- MT
- S
- WC. Describe Word Cloud terms and their counts.
- CT. Describe Category Tree Fields, Items, and their respective counts.
For more information on the Google Search Protocol tags, see https://developers.google.com/custom-search/docs/xml_results.
Word Cloud and Category Tree Data Returned in Magnify Search XML Output
Word Cloud data is returned in a WC element that includes the count and word attributes. Each attribute contains a comma-separated list where the parallel order between count and word correlate. This means that the first word has a count of the first number listed.
Category Tree data is returned in a CT element with a CAT sub-element for each Category field with attributes for the source field name (fieldname) and the text to display in the interface (displayname). Each Category field has VAL sub-elements for each of the Category values (name) and the corresponding counts (count). The following image shows an example of a Magnify Search XML output document, where the data identified by the CT element is used to build the Category Tree in the Magnify search results.
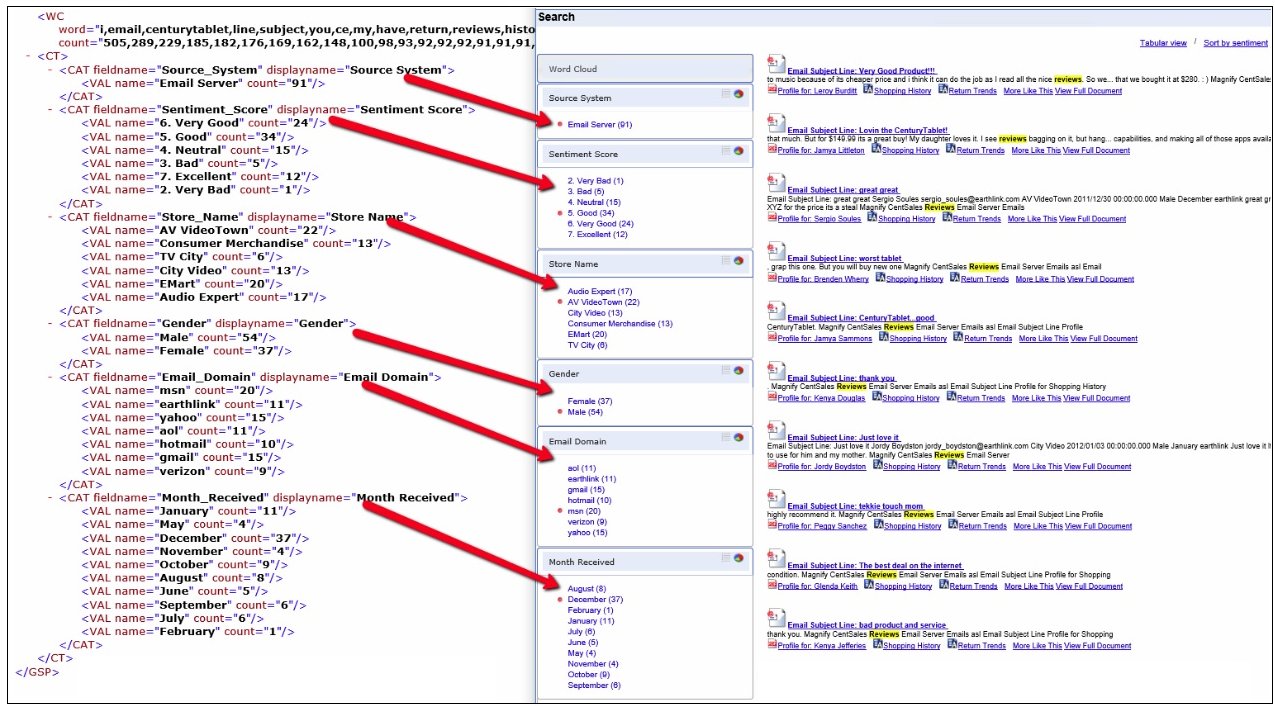
Showing Search Results in the Category Tree That Have Blank or Empty Category Values
By default, blank or empty values are not represented in the Category Tree.
For example, the following feed procedure creates blank category values for all Country=England results and the Category Value 'Present' for all other countries.
In this scenario, the Category Tree is represented as shown in the following image.
The developer of the feed procedure must determine what constitutes a blank versus empty value. Based on this decision, the developer must use a DECODE or IF/THEN/ELSE to provide a real representative value illustrating differences between EMPTY, BLANK, NULL, UNDEFINED, if and when relevant.
To summarize, values of type EMPTY, BLANK, NULL, and UNDEFINED (if required to be represented in the Category Tree) should use the DECODE or IF/THEN/ELSE to assign a physical textual representation.
| WebFOCUS | |
|
Feedback |